type
Post
status
Published
date
Mar 14, 2026 05:51
slug
rec-weekly-2026-W11-en
summary
Two technical threads dominate Week 11 of 2026 (March 8–14) in recommendation system research. First, generative recommendation (GR) is undergoing full-stack optimization — transitioning from "making it work" to "making it work well, fast, and fairly" — Netflix/Meta's exponential reward-weighted SFT addresses post-training alignment, LinkedIn's causal attention reformulation halves sequence length, Kuaishou's FP8 quantization reduces OneRec-V2 inference latency by 49%, and Alibaba's differentiable geometric indexing eliminates long-tail bias at its root. Five papers advance GR's industrial maturity across five dimensions. Second, LLM-based recommendation is shifting from "single-pass inference" toward an agentic paradigm — Meta's VRec inserts verification steps into reasoning chains, Meituan's RecPilot replaces traditional recommendation lists with a multi-agent framework, USTC's TriRec introduces tri-party coordination for the first time, and RUC/JD's RecThinker enables autonomous tool invocation.
tags
推荐系统
周报
论文
category
icon
password
priority
Weekly Overview
Two technical threads dominate Week 11 of 2026 (March 8–14) in recommendation system research. First, generative recommendation (GR) is undergoing full-stack optimization — transitioning from "making it work" to "making it work well, fast, and fairly" — Netflix/Meta's exponential reward-weighted SFT addresses post-training alignment, LinkedIn's causal attention reformulation halves sequence length, Kuaishou's FP8 quantization reduces OneRec-V2 inference latency by 49%, and Alibaba's differentiable geometric indexing eliminates long-tail bias at its root. Five papers advance GR's industrial maturity across five dimensions. Second, LLM-based recommendation is shifting from "single-pass inference" toward an agentic paradigm — Meta's VRec inserts verification steps into reasoning chains, Meituan's RecPilot replaces traditional recommendation lists with a multi-agent framework, USTC's TriRec introduces tri-party coordination for the first time, and RUC/JD's RecThinker enables autonomous tool invocation.
Representation learning is equally active. Huawei's RF-Mem brings dual-process cognitive theory into the retrieval pipeline, Amazon's P²GNN augments GNN message passing with prototype sets and ranks first across 18 datasets, and separate work explores extracting retrieval embeddings directly from LLM hidden states. Additionally, federated recommendation, machine unlearning, and privacy compliance each see multiple noteworthy contributions — signaling that infrastructure-level privacy requirements for recommendation systems are maturing rapidly.
Architecture and Post-Training Optimization for Generative Recommendation
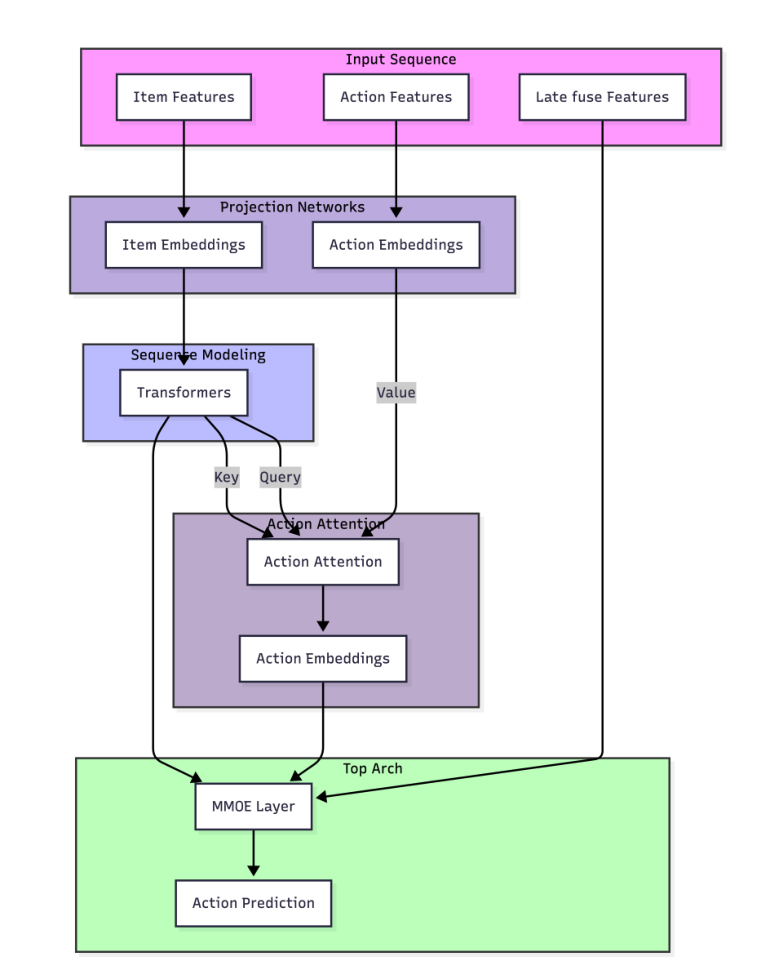
Generative recommendation is undergoing a critical transition from proof-of-concept to industrial deployment. Since HSTU established the GR paradigm, the central challenge has shifted from "how to model sequences with Transformers" to system-level full-stack optimization. This week's five papers advance this direction across post-training alignment, causal attention reformulation, inference quantization, RL fine-tuning, and end-to-end indexing.
Robust Post-Training for Generative Recommenders (2603.10279)
This joint work from Netflix and Meta targets the core pain point of GR post-training: RLHF is prone to reward hacking in recommendation settings, offline RL requires unobtainable propensity scores, and online interaction is infeasible in production. Their solution is surprisingly simple — exponential reward-weighted SFT, with the weight formula reduced to $w = \exp(r/\lambda)$. Theoretically, the method provides policy improvement guarantees under noisy rewards, with the gap growing only logarithmically with catalog size. In practice, the temperature parameter $\lambda$ offers a quantifiable tradeoff between robustness and improvement. Across three open-source datasets and one proprietary dataset, the method consistently outperforms RLHF variants including DPO, IPO, and KTO.
The paper explicitly validates on SASRec, HSTU, and OneRec as base architectures. OneRec-V2 adopts Duration-Aware Reward Shaping and Adaptive Ratio Clipping — a separate preference alignment path — yet this paper achieves comparable or superior results with a substantially lighter approach, offering direct reference value for industrial deployment.
Beyond Interleaving: Causal Attention Reformulations for Generative Recommender Systems (2603.10369)
This LinkedIn paper conducts a fundamental rethinking of sequence modeling in GR. Current mainstream GR systems (such as Meta's HSTU) interleave item tokens and action tokens, but this design doubles the sequence length, introduces quadratic computational overhead, and forces the Transformer to implicitly disentangle semantically incompatible heterogeneous tokens. The paper proposes two architectures — AttnLFA and AttnMVP — whose core idea is to explicitly encode item→action causal dependencies rather than letting the attention mechanism infer them. The results demonstrate a 50% reduction in sequence complexity, evaluation loss improvements of 0.29% and 0.80%, and training time reductions of 23% and 12%, respectively.
HSTU achieved a 12.4% online metric improvement across multiple Meta product lines, but the efficiency cost of its interleaved sequence design has been accepted as a given. LinkedIn's work demonstrates that this cost is not inherent — explicit modeling of causal structure can improve both effectiveness and efficiency simultaneously.
Quantized Inference for OneRec-V2 (2603.11486)
The Kuaishou team transfers mature FP8 quantization techniques from the LLM domain to OneRec-V2 — an effort that appears incremental but carries substantial implications. Traditional recommendation model weights and activations typically exhibit high-amplitude, high-variance distributions that are highly sensitive to quantization perturbation. Through distributional analysis, the paper empirically demonstrates that OneRec-V2's numerical statistics are substantially closer to LLMs than to traditional recommendation models — itself a notable signal that the GR paradigm is converging toward the LLM paradigm.
OneRec-V2's original Lazy Decoder-Only architecture already reduced total computation by 94% and training resources by 90%, supporting scaling to 8B parameters. On top of this, FP8 quantization further achieves a 49% reduction in end-to-end inference latency and a 92% throughput improvement, with online A/B tests confirming no degradation in core metrics. Previously, xGR achieved 3.49x throughput improvement through decoupled KV caching, and RelayGR supported 1.5x longer sequences through cross-stage relay inference — this paper completes the GR inference optimization picture from the numerical precision dimension.
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement Learning (2603.11901)
FlexRec addresses a pragmatic yet overlooked problem: how can LLM-based recommenders switch optimization objectives on demand across different scenarios? The paper introduces RL post-training under a closed-set autoregressive ranking formulation. The core innovation lies in causal item-level rewards based on counterfactual swapping — performing counterfactual swaps within the remaining candidate pool for fine-grained credit assignment, combined with critic-guided uncertainty-aware scaling to stabilize training. NDCG@5 improves by up to 59%, Recall@5 by up to 109.4%, and Recall@5 under generalization settings still improves by 24.1%. This work extends Rec-R1 with substantive advances in reward design and training stability. However, validation remains offline only, with no large-scale online A/B testing.
Differentiable Geometric Indexing for End-to-End Generative Retrieval (2603.10409)
The Alibaba team identifies two deep-seated contradictions in the index construction stage of generative retrieval: the non-differentiability of discrete indices blocks gradient propagation (Optimization Blockage), and unnormalized inner product objectives cause popular items to dominate long-tail items in geometric space (Geometric Conflict). DGI addresses both simultaneously — Soft Teacher Forcing with Gumbel-Softmax establishes a fully differentiable path. Symmetric Weight Sharing then aligns the quantizer's index space with the retriever's decoding space. Scaled cosine similarity on a unit hypersphere replaces inner product logits, geometrically decoupling popularity bias from semantic relevance. Online e-commerce platform validation demonstrates that DGI performs particularly well in long-tail scenarios. Prior generative retrieval work such as TIGER uses RQ-VAE for discrete tokenization — all fundamentally limited by the disconnect between index construction and downstream retrieval objectives. DGI is the first to address this problem simultaneously from both differentiability and geometric structure perspectives.
Together, these five papers make the case that GR's core challenge has shifted from "how to model sequences with Transformers" to system-level full-stack optimization — post-training alignment (exponential reward weighting vs. RL), attention structure (causal reformulation vs. interleaving), inference efficiency (FP8 quantization), and index design (differentiable geometry). Each component is converging toward LLM engineering practices while adapting to the unique constraints of recommendation scenarios.
LLM Agents and Reasoning-Enhanced Recommendation
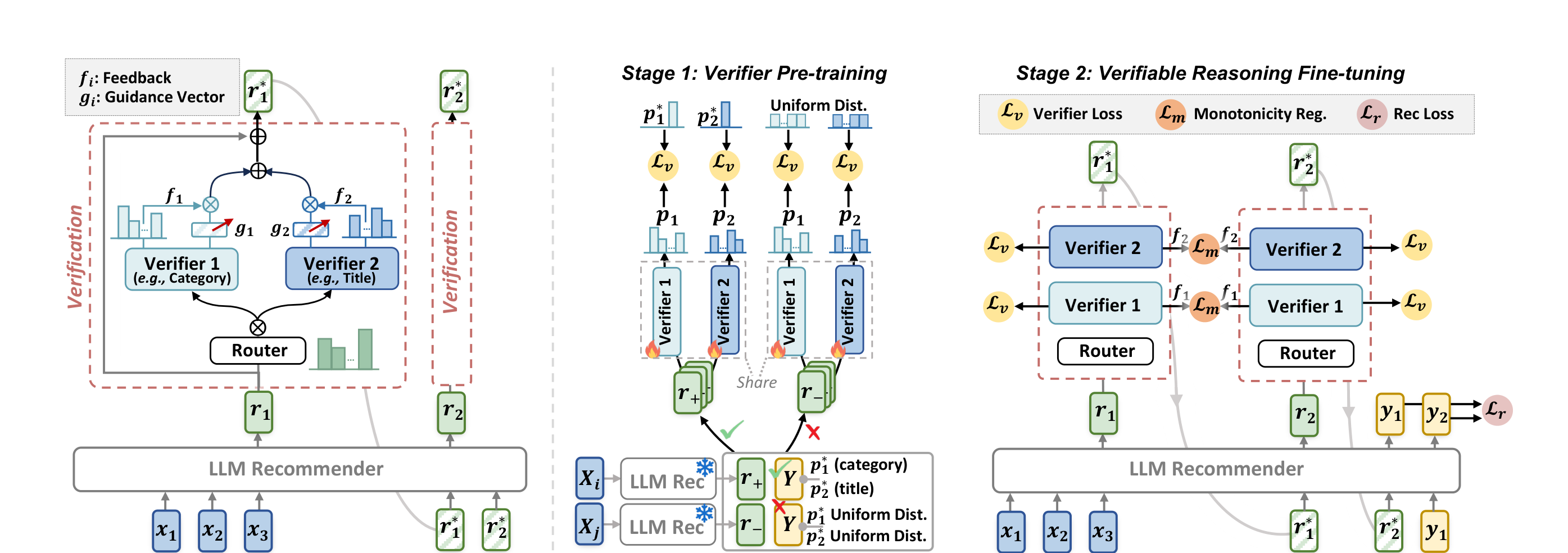
Recommendation systems are undergoing a fundamental role shift: from passive list filters to agents capable of proactive investigation, reasoning, and verification. This week's five papers drive this transformation from the angles of verifiable reasoning, deep research paradigms, multi-party coordination, tool-augmented reasoning, and autonomous memory retrieval.
Verifiable Reasoning for LLM-based Generative Recommendation (2603.07725)
Meta and the National University of Singapore jointly propose VRec. It targets the core flaw of the "reason-then-recommend" paradigm in current LLM recommendation: reasoning chains lack intermediate verification, leading to homogenized reasoning and error accumulation. VRec's solution inserts verification steps, forming a "reason-verify-recommend" triplet. Specifically, VRec employs a mixture of verifiers to ensure comprehensive validation across multiple dimensions of user preferences, while introducing a proxy prediction objective to guarantee the verifiers' own reliability — unreliable verifiers render verification meaningless. Experiments on four real-world datasets demonstrate that VRec substantially improves recommendation quality and scalability without sacrificing efficiency.
Prior work such as Reason4Rec has already established that reasoning chains benefit recommendation, but VRec reveals a deeper issue: the quality of reasoning chains requires explicit constraints rather than blind trust in LLM autoregressive generation. This echoes the recent approach of DiffuReason, which uses diffusion models to denoise and refine reasoning outputs — both convey the same message: LLM reasoning outputs require "post-processing."
Deep Research for Recommender Systems (2603.07605)
RecPilot, a collaboration between Meituan and RUC, takes a more radical step: it eliminates the recommendation list entirely, replacing it with comprehensive research reports. This is not an incremental improvement but a redefinition of the interaction paradigm. RecPilot comprises two core agents: a user trajectory simulation agent that autonomously explores the item space, and a self-evolving report generation agent that synthesizes exploration results into structured decision reports. Traditional recommendation offloads the cognitive burden of "explore-compare-synthesize" entirely to users — RecPilot lets the system proactively shoulder this work. Experiments on public datasets demonstrate that the generated reports not only model user behavior effectively but also exhibit high persuasiveness, substantially reducing users' item evaluation costs.
This direction — alongside ChainRec's tool-chain routing and RecMind's agent-based recommendation — points toward a future where recommendation system output is no longer limited to item lists but may include investigation reports, comparative analyses, or decision recommendations. RecPilot currently validates only on public datasets and remains distant from production deployment in Meituan's actual scenarios.
Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation (2603.10673)
USTC's TriRec framework addresses a neglected structural issue: existing agent-based recommendation is uniformly user-centric, treating items as passive entities and leading to exposure concentration and poor long-tail representation. TriRec introduces tri-party coordination for the first time — user utility, item exposure, and platform fairness. In a two-stage architecture, Stage 1 grants item agents personalized self-promotion capabilities to break through cold-start barriers, while Stage 2 employs a platform agent for multi-objective sequential re-ranking that balances all three parties' interests.
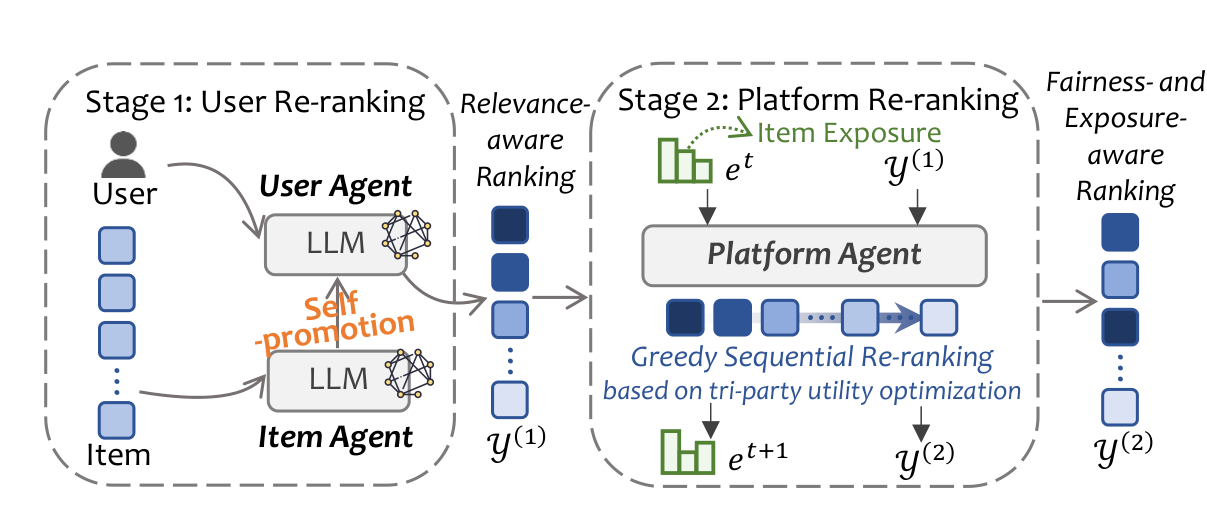
The counterintuitive result: item self-promotion can simultaneously improve both fairness and recommendation quality, challenging the conventional assumption that "relevance and fairness must be traded off." From AgentCF's approach of modeling both users and items as agents for collaborative learning, to TriRec's introduction of a platform agent as a third-party arbiter, the participants in agent-based recommendation are expanding from bilateral to multilateral.
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation (2603.09843)
RecThinker, a collaboration between RUC and JD, addresses the information acquisition challenge in agent-based recommendation. Existing methods either rely on static predefined workflows or reason under limited information, producing suboptimal recommendations when facing fragmented user profiles or sparse item metadata. RecThinker adopts an Analyze-Plan-Act paradigm: it first assesses the sufficiency of user-item information, then autonomously plans a tool invocation sequence to fill information gaps. The tool suite spans user-side, item-side, and collaborative information dimensions. The training pipeline includes an SFT stage to internalize high-quality reasoning trajectories and an RL stage to optimize decision accuracy and tool usage efficiency. Similar to ChainRec's approach of constructing tool libraries from expert trajectories, RecThinker also emphasizes the learnability of tool invocation — but goes further by delegating the "when to invoke tools" judgment to autonomous model decisions.
TA-Mem: Tool-Augmented Autonomous Memory Retrieval for LLM in Long-Term Conversational QA (2603.09297)
Although TA-Mem is positioned for long-term conversational QA, its core design — a multi-index memory store paired with a tool-augmented autonomous retrieval agent — offers direct applicability to conversational recommendation. Traditional memory retrieval relies on predefined workflows or static top-k similarity matching. TA-Mem lets the retrieval agent autonomously select retrieval tools — key-value lookup or similarity search — and decide through multi-round iteration whether additional retrieval is needed. It substantially outperforms baselines on the LoCoMo dataset. In conversational recommendation scenarios where user preferences evolve throughout the dialogue, TA-Mem's adaptive retrieval mechanism handles this dynamism more effectively than fixed pipelines.
These five papers collectively outline a clear trend: LLM-based recommendation is moving from "single-pass inference" toward a "multi-step, verifiable, tool-assisted" agentic paradigm, where system proactiveness and autonomous decision-making become the core competitive differentiators.
Retrieval Representation Learning and Embedding Space Optimization
This week's representation learning papers all wrestle with the same question: who should define the embedding space — standalone encoders, GNN message passing, or LLM hidden states themselves? Five papers approach this question from different entry points and arrive at markedly different answers.
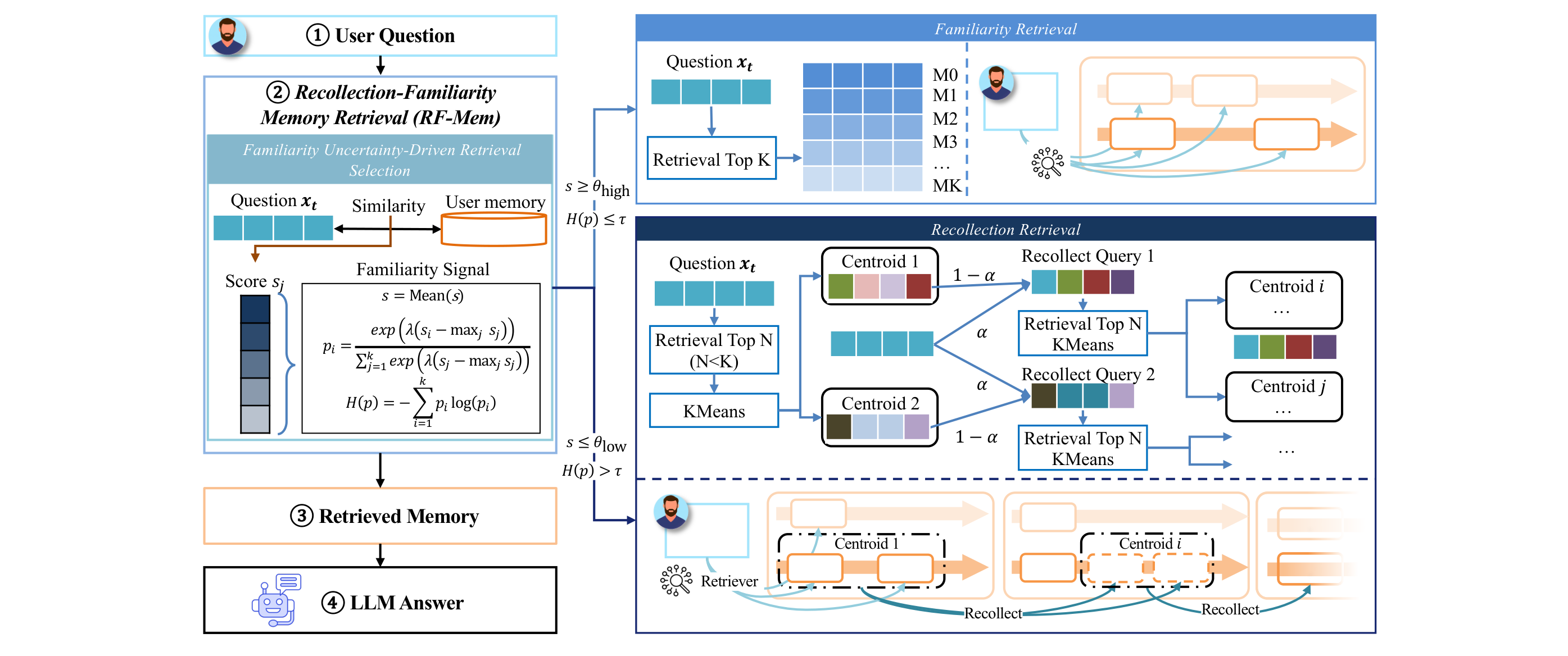
Evoking User Memory: Personalizing LLM via Recollection-Familiarity Adaptive Retrieval (2603.09250)
RF-Mem, proposed by Huawei jointly with Dalian University of Technology and others, brings dual-process memory theory from cognitive science into the retrieval pipeline. The core observation: existing RAG systems either stuff the entire user history into the prompt — with uncontrollable costs — or perform a single top-K similarity retrieval that captures only surface-level matches. RF-Mem quantifies "familiarity" through two signals — mean score and entropy. High familiarity routes to the fast top-K path; low familiarity activates the recollection path, which first clusters candidate memories, then uses alpha-mix to iteratively expand the query's evidence coverage in embedding space, simulating human associative reconstruction.
The elegance of this design lies in using entropy as the routing signal — low entropy indicates high consistency in the retriever's judgment for the current query, allowing direct results; high entropy signals ambiguous neighborhood distributions in embedding space, requiring deeper contextual reconstruction. Across three benchmarks, RF-Mem consistently outperforms both single-pass retrieval and full-context reasoning under fixed budget and latency constraints. Compared to RLMRec's cross-view alignment framework — which aligns LLM semantic space with collaborative signals through mutual information maximization — RF-Mem takes an adaptive routing approach on the retrieval side. It does not alter how the embedding space is constructed but rather dynamically dispatches at the usage layer.
P²GNN: Two Prototype Sets to boost GNN Performance (2603.09195)
This Amazon paper targets two persistent weaknesses of MP-GNNs: over-reliance on local neighborhoods and ineffectiveness against heterophilic edges. P²GNN's solution introduces two prototype sets: the first serves as "global neighbors" for all nodes, enabling every node to access global context during message passing; the second achieves denoising by aligning messages to cluster prototypes. The design is plug-and-play, stackable on top of GCN, GAT, and GraphSAGE. Experiments across 18 datasets — covering proprietary e-commerce data and public benchmarks — achieve the top average ranking on both node recommendation and classification tasks, outperforming production models in e-commerce scenarios.
From a representation learning perspective, prototypes essentially anchor a set of global reference points in embedding space. Spotify's 2T-HGNN introduces global information through heterogeneous graph structure (achieving +46% new audiobook start rate), while P²GNN achieves a similar effect through a lighter prototype mechanism without requiring explicit heterogeneous relation modeling.
One Model Is Enough: Native Retrieval Embeddings from LLM Agent Hidden States (2603.08429)
This paper poses a radical but reasonable question: when an LLM agent generates retrieval queries, its hidden states already encode the complete conversational context — why run a separate embedding model? The authors add a lightweight projection head on top of the LLM, directly mapping hidden states to embedding space through joint training with alignment loss, contrastive loss, and ranking distillation loss. On the QReCC conversational search benchmark, the method retains 97% of baseline retrieval quality (Recall@10 and MRR@10) while eliminating the infrastructure complexity and latency introduced by a standalone embedding model.
This follows the same logic as NoteLLM, which compresses notes into a single special token and learns embeddings through contrastive learning — both let the LLM produce its own embeddings rather than relying on external encoders. However, a 97% retention rate implies a quality gap that may translate to non-trivial business impact in industrial settings.
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning (2603.08159)
Tsinghua's TIER method focuses on the structural properties of embedding spaces — most existing text-rich network (TRN) representation learning models only capture flat semantics, ignoring coarse-to-fine hierarchical structure. TIER proceeds in three steps. First, similarity-guided contrastive learning constructs a clustering-friendly embedding space. Then hierarchical K-Means with LLM-refined cluster results builds upon it. Finally, a regularization loss based on the cophenetic correlation coefficient forces the embedding space to maintain hierarchical structure consistency. This regularization design is noteworthy — rather than simply adding hierarchical constraints, it uses a mathematical measure from dendrogram clustering to quantify the hierarchical fidelity of the embedding space. The method substantially outperforms existing approaches across datasets from multiple domains.
Why Large Language Models can Secretly Outperform Embedding Similarity in Information Retrieval (2603.08077)
This paper from the University of Groningen provides a compelling theoretical perspective: embedding similarity is fundamentally a myopic interpretation of "relevance." The authors compare LLM-Based Relevance Judgment Systems (LLM-RJS) with Neural Embedding Retrieval Systems (NERS) on TREC-DL 2019 and do not observe substantial improvements — but the cause lies not in the models but in the evaluation. Deeper analysis reveals that human annotations themselves suffer from myopia, and the "false positives" produced by LLM-RJS through reasoning are actually annotation errors. This conclusion provides a thought-provoking counterpoint to the embedding optimization work above: as we continuously refine the geometric structure of embedding spaces, the bottleneck may not reside in the representations themselves but in the fact that how we measure "relevance" needs updating.
Taken together, these five papers outline a clear trend: representation learning is evolving from "training a good embedding model" toward "deeply coupling embedding spaces with usage contexts" — whether through RF-Mem's adaptive routing, P²GNN's global prototype anchoring, or extracting embeddings directly from LLM hidden states, none treat the embedding space as a static, independently optimized component.
Federated Recommendation, Privacy Compliance, and Other Directions
This week's miscellaneous topics span federated recommendation, machine unlearning, retrieval compression, ad bidding, and classical model generalization. Each pushes its subfield's fundamentals forward.
Sharpness-Aware Minimization for Generalized Embedding Learning in Federated Recommendation (2603.11503)
Item embedding generalization has long been a thorny problem in federated recommendation — local data in cross-device settings is both heterogeneous and sparse, causing embeddings to easily overfit to local distributions. FedRecGEL reframes federated recommendation as an item-centric multi-task learning problem, treating each client as a "task." Under this framework, it introduces Sharpness-Aware Minimization (SAM) to find solutions in flat regions of the loss landscape, thereby stabilizing global embedding training. Recall@20 improves by 3.2%–8.7% over FedAvg, FedProx, SCAFFOLD, and other baselines across four datasets. The approach is clean, though industrial-scale validation is still absent. SAM has seen limited prior application in recommendation — this optimizer-level approach to federated generalization is a fresh angle.
Federated Learning and Unlearning for Recommendation with Personalized Data Sharing (2603.11610)
FedShare addresses a more fine-grained privacy control problem in federated recommendation: users may selectively share portions of their interaction data and subsequently withdraw that sharing. The framework leverages shared data on the server side to construct higher-order user-item graphs and aligns local and global representations through contrastive learning. The unlearning stage is the highlight — a contrastive unlearning mechanism selectively removes the influence of withdrawn data using only a small number of historical embedding snapshots, avoiding the overhead of storing extensive gradient histories required by existing methods. Effectiveness of both the learning and unlearning stages is validated on three public datasets. Together with FedRecGEL, this reflects federated recommendation's evolution from "functional" to "fine-grained control."
Modeling Stage-wise Evolution of User Interests for News Recommendation (2603.10471)
The temporal nature of news recommendation demands that user interest modeling cover both short-term and long-term dynamics. This paper partitions historical interaction graphs into stage-wise temporal subgraphs, uses GCN to capture global collaborative signals, then applies a dual approach on local subgraphs: LSTM models the gradual evolution of recent interests while self-attention captures long-range temporal dependencies. The architecture is not particularly novel — BST (2019) already introduced self-attention for behavioral sequence modeling, and DSIN performed session-level segmentation — but the explicit decoupling of graph structure and temporal modeling in a news setting still holds value. The method consistently outperforms strong baselines on two large-scale datasets, though online validation is absent.
A Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models (2603.09933)
The storage overhead of ColBERT-style late-interaction models has been a persistent deployment pain point — every document token must retain a dense vector. Existing pruning methods rely on IDF statistics or positional heuristics without theoretical grounding. This paper provides an elegant formalization using hyperspace geometry: token pruning is modeled as a Voronoi cell estimation problem in embedding space, where each token's importance is measured by the "influence range" of its Voronoi region. The method achieves 30%–50% index compression on MS MARCO and TREC DL while preserving retrieval quality. Recently, Col-Bandit achieves 5x MaxSim FLOPs reduction through query-side zero-shot pruning, and FastLane uses learnable routing for 30x computation reduction — this paper's document-side Voronoi perspective complements both.
ERASE — A Real-World Aligned Benchmark for Unlearning in Recommender Systems (2603.08341)
Machine unlearning in recommendation systems has lacked practical evaluation standards. ERASE fills this gap: it covers collaborative filtering, session-based recommendation, and next-basket recommendation, evaluating 7 unlearning algorithms across 9 datasets and 9 SOTA models, generating over 600GB of reusable experimental data. The key finding is that approximate unlearning can match full retraining in some scenarios, but robustness varies substantially — general-purpose methods perform poorly on attention and RNN models under repeated unlearning scenarios, while recommendation-specific unlearning methods prove more stable. Combined with FedShare's contrastive unlearning design, unlearning and privacy compliance are emerging as an independent research axis for recommendation systems.
A Lightweight MPC Bidding Framework for Brand Auction Ads (2603.07721)
This ByteDance paper takes a distinctive approach — brand advertising differs from performance advertising in that user interaction patterns are stable and feedback loops are fast, eliminating the need for complex ML models. Based on this insight, the paper proposes replacing traditional machine learning bidding with a Model Predictive Control (MPC) framework. The core uses online isotonic regression to directly construct monotonic bid-to-spend and bid-to-conversion mappings from streaming data. Computational overhead is minimal and the system runs entirely online. Simulation results demonstrate substantially better spending efficiency and cost control compared to baselines. The approach is pragmatic, but only simulation results are available — no online A/B testing. For a platform with ByteDance's traffic volume, this gap weakens the contribution.
Generalizing Linear Autoencoder Recommenders with Decoupled Expected Quadratic Loss (2603.07402)
Linear autoencoders (LAE) continue to attract attention in recommendation for their simplicity and efficiency. Steck's 2020 EDLAE admits a closed-form solution only when hyperparameter b=0, limiting model capacity. DEQL decouples the objective function into a Decoupled Expected Quadratic Loss, deriving closed-form solutions for the b>0 range with computational feasibility guaranteed through the Miller matrix inverse theorem. Recall@20 and NDCG@20 improve by approximately 1%–3% over the b=0 baseline on MovieLens-1M and Netflix. An incremental improvement but a solid direction — in an era dominated by deep models, the mathematical elegance and interpretability of LAE methods still earn their place.
The two federated recommendation papers (FedRecGEL, FedShare) and the unlearning benchmark (ERASE) collectively point to a trend: privacy compliance and data sovereignty are transitioning from "nice-to-have" to infrastructure-level requirements for recommendation systems, with the associated methodologies maturing rapidly.
Directions to Watch
Full-Stack Industrialization of Generative Recommendation
This week's five GR papers simultaneously cover post-training alignment, attention architecture, inference quantization, RL fine-tuning, and end-to-end indexing — this multi-dimensional concurrent progress indicates that GR has entered a systems engineering phase. Exponential reward-weighted SFT (Netflix/Meta) is highly attractive for industrial adoption due to its simplicity and theoretical guarantees. FP8 quantization (Kuaishou) validates that GR model numerical properties are sufficiently close to LLMs to directly reuse the LLM inference optimization toolchain. AttnLFA/AttnMVP (LinkedIn) demonstrates that the efficiency cost of interleaved sequence design is not inherent. Industrial teams at Netflix, Meta, Kuaishou, LinkedIn, and Alibaba all contributed within a single week — GR will likely see more large-scale deployment cases in the second half of 2026. The likely next step is combining these optimizations — for instance, an integrated solution of causal attention + FP8 quantization + exponential reward weighting.
Multi-Party Coordination in Agentic Recommendation
Agentic recommendation is expanding from "user proxy" to multi-party participation. TriRec (USTC) introduces item agents and platform agents for the first time, with experiments demonstrating that item self-promotion can simultaneously improve both fairness and accuracy. RecPilot (Meituan/RUC) eliminates recommendation lists entirely, replacing the traditional interaction paradigm with comprehensive reports. RecThinker (RUC/JD) and TA-Mem refine agents' information acquisition capabilities at the tool invocation and memory retrieval levels. These works remain distant from industrial deployment, but collectively sketch the evolution of recommendation systems from "passive filters" toward "proactive assistants." Promising application scenarios include high-value decisions (real estate, automobiles, education) and contexts requiring deep information synthesis.
Privacy Compliance as an Infrastructure-Level Requirement
FedRecGEL stabilizes embedding generalization in federated recommendation from the optimizer level, FedShare supports fine-grained data sharing and withdrawal, and ERASE provides the first unlearning benchmark covering three recommendation task types (600GB+ of reusable data). The combined signal from these three papers is clear: federated learning, selective unlearning, and privacy compliance are converging from scattered academic explorations into a coherent technology stack. As GDPR enforcement intensifies and data protection regulations tighten worldwide, privacy capabilities in recommendation systems are shifting from "differentiator" to "table stakes." Academic teams at Zhejiang University, University of Technology Sydney, and University of Amsterdam continue to push this forward, but large-scale industrial validation remains the critical gap.
Paper Roundup
Architecture and Post-Training Optimization for Generative Recommendation
Robust Post-Training for Generative Recommenders: Why Exponential Reward-Weighted SFT Outperforms RLHF — Proposes exponential reward-weighted SFT (w=exp(r/λ)) for GR post-training with theoretical policy improvement guarantees; consistently outperforms DPO/IPO/KTO and other RLHF variants across four datasets.
Beyond Interleaving: Causal Attention Reformulations for Generative Recommender Systems — Proposes AttnLFA/AttnMVP architectures that eliminate item-action interleaving dependency; halves sequence length, accelerates training by 12–23%, and improves evaluation loss by 0.29–0.80%.
Quantized Inference for OneRec-V2 — Adapts FP8 quantization to OneRec-V2; reduces inference latency by 49%, improves throughput by 92%, with online A/B tests confirming no degradation in core metrics.
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement Learning — RL post-training framework based on causal item-level rewards and uncertainty-aware scaling; NDCG@5 improves by up to 59%, Recall@5 by up to 109.4%.
Differentiable Geometric Indexing for End-to-End Generative Retrieval — Resolves optimization blockage and long-tail bias in GR through Gumbel-Softmax fully differentiable indexing and hyperspherical cosine similarity; validated on an online e-commerce platform.
LLM Agents and Reasoning-Enhanced Recommendation
Verifiable Reasoning for LLM-based Generative Recommendation — Proposes the reason-verify-recommend paradigm VRec with mixture of verifiers inserting intermediate verification during reasoning; validated across four datasets.
Deep Research for Recommender Systems — Proposes RecPilot, a multi-agent framework replacing traditional list-based recommendation with user trajectory simulation and self-evolving report generation.
Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation — First tri-party agent framework TriRec introducing item self-promotion and platform multi-objective re-ranking; simultaneously improves accuracy and fairness.
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation — Analyze-Plan-Act paradigm with dedicated tool suite and SFT+RL training; enables autonomous information acquisition in recommendation.
TA-Mem: Tool-Augmented Autonomous Memory Retrieval for LLM in Long-Term Conversational QA — Multi-index memory store with tool-augmented retrieval agent; adaptively selects retrieval strategies in long-term conversational settings.
Retrieval Representation Learning and Embedding Space Optimization
Evoking User Memory: Personalizing LLM via Recollection-Familiarity Adaptive Retrieval — Draws on cognitive science dual-process theory; adaptively switches between fast top-K and iterative recollection retrieval paths based on familiarity uncertainty.
P²GNN: Two Prototype Sets to boost GNN Performance — Augments GNN message passing with global neighbor prototypes and cluster alignment prototypes; ranks first across 18 datasets, outperforming production models in e-commerce scenarios.
One Model Is Enough: Native Retrieval Embeddings from LLM Agent Hidden States — Lightweight projection head maps LLM hidden states directly to retrieval vectors, eliminating the standalone embedding model; retains 97% retrieval quality.
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning — Constructs implicit taxonomies and aligns embeddings through cophenetic correlation coefficient regularization; captures both coarse and fine-grained semantics.
Why Large Language Models can Secretly Outperform Embedding Similarity in Information Retrieval — Analysis reveals that LLM reasoning can overcome the "myopia" limitation of embedding similarity, but existing annotated datasets cannot fully evaluate this advantage.
Federated Recommendation, Privacy Compliance, and Others
Sharpness-Aware Minimization for Generalized Embedding Learning in Federated Recommendation — Introduces sharpness-aware minimization to stabilize item embedding learning in federated recommendation; Recall@20 improves by 3.2%–8.7%.
Federated Learning and Unlearning for Recommendation with Personalized Data Sharing — Federated recommendation framework FedShare supporting personalized data sharing and contrastive unlearning.
Modeling Stage-wise Evolution of User Interests for News Recommendation — Models user interest evolution through stage-wise temporal subgraphs, combining LSTM and self-attention to capture multi-scale dynamics.
A Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models — Voronoi geometry-based token pruning method; reduces ColBERT index storage by 30–50%.
ERASE — A Real-World Aligned Benchmark for Unlearning in Recommender Systems — Large-scale unlearning benchmark covering three recommendation task types; generates 600GB+ of reusable experimental data.
A Lightweight MPC Bidding Framework for Brand Auction Ads — Lightweight MPC bidding framework for brand advertising; replaces complex ML models with online isotonic regression.
Generalizing Linear Autoencoder Recommenders with Decoupled Expected Quadratic Loss — Generalizes EDLAE to the b>0 hyperparameter range; Recall@20 and NDCG@20 improve by 1–3%.