type
Post
status
Published
date
Mar 10, 2026
slug
10-habits-double-claude-code-success-zh
summary
从 context 管理到 harness 设计,10 个让你的 coding agent 告别 context rot、成功率翻倍的实用习惯。
tags
Agentic Engineering
Harness Engineering
category
Agentic Engineering
icon
password
priority
3
一个 coding agent 在第 5 分钟和第 35 分钟,是两个完全不同的东西。

Chroma Research 测了 18 个大模型,结论很反直觉——context 越长,性能越差。不是接近上限时才下降,是从一开始就在下降。Liu et al. 的 "Lost in the Middle" 更直观:相关信息落在 context 中间位置时,模型性能下降超过 30%。在 agent 场景下这个问题被急剧放大:每次读文件、每次 grep、每次走进死胡同,这些信息都留在 context window 里。Context 像内存泄漏一样膨胀,模型性能随之持续衰减——这就是 context rot。实操数据显示,任务时间翻倍,失败率翻四倍。
Phil Schmid 说得好:"Most agent failures are not model failures anymore, they are context failures." CodeScene 的研究给了另一个硬数据:在健康代码上 agent 成功率超过 60%,在烂代码上只有 20%——同一个 agent,同一个 prompt,三倍差距。Karpathy 从最初推广 vibe coding 到明确转向 agentic engineering,也是因为意识到了同一个问题:自由发挥不可持续,纪律才能规模化。
这 10 个简单习惯就是那些纪律。文中以 Claude Code 为例,但核心原则适用于所有 coding agent。不需要搭建复杂系统,不需要改工具链。大多数 agent 用户根本没做这些基本功——认真执行就是降维打击。
技巧围绕两个核心展开:把 context 当内存来管,和给 agent 设计好 harness。后者本质上也是在让 context 不爆炸。
把 Context 当内存来管
Context window 就是 agent 的工作内存。内存不是无限的,用满了系统就卡。Context window 也一样——超过 50% 时模型就开始变笨,成本也开始飙升。大多数人的习惯是等系统自己触发压缩,就像 Java 的 Full GC——等到触发的时候已经晚了。正确的做法不是事后压缩,而是从源头控制,根本不让 context 膨胀到需要压缩。最好的 GC 是不需要 GC。
前三个技巧是手动内存管理——什么时候释放、怎么持久化状态、初始内存里装了什么。后三个技巧是机制层面的自动管理——让每次分配天然就小,让隔离和回收内建在工作流里。
技巧 1:新任务新 Session
做完一个任务,
/clear,开始下一个。就这么简单。你不会在一个浏览器 tab 里同时做 5 件不相关的事。但很多人用 agent 时就是这样——改完 bug 接着写新功能,写完功能又去调配置,所有对话历史堆在同一个 context window 里。
这样做有两个直接后果:
- 浪费钱。 无关 token 每轮对话都要重新处理。一个 50K token 的 context 里有 30K 是上一个任务的残留,你每次交互都在为这 30K 付费。
- 模型变傻。 前面说的 context rot 在这里直接生效。无关信息越多,模型对当前任务的注意力越分散,输出质量肉眼可见地下降。
进阶用法:两次修正失败就重来。 如果同一个问题你纠正了两次 agent 还是搞不对,不要继续在这个 session 里纠缠。context 已经被污染了——之前的错误尝试、你的纠正、agent 的道歉,全都变成了噪音。
/clear,花 30 秒写一个更精确的初始 prompt,重新开始。大多数时候,干净 context 下的第一次尝试比污染 context 下的第五次修正效果更好。退而求其次:
/compact <指令>。 如果你实在没法清 session(比如任务还没做完),至少做有方向的压缩,而不是无脑 /compact。比如 /compact 聚焦 API 变更部分,丢弃调试过程。你还可以在 CLAUDE.md 里加一条规则:"压缩时必须保留所有已修改文件列表和测试命令"——这样即使触发压缩,关键信息也不会丢。跨 Session 传递状态:progress.md。 清完 context 自然有个疑问:状态不就丢了吗?上午做了一半,下午怎么接?答案是把状态写进文件。每个 session 结束时更新 progress.md——当前进度、关键决策、下一步待办。下个 session 开头读这个文件,3 秒恢复上下文。你不需要维持长 session 来"记住"进度。Git 历史是天然的补充——commit message + diff 让新 session 快速理解"做了什么、为什么这么做"。文件记意图,git 记事实。Context window 是临时的,文件系统是持久的——把状态写进文件,每个 session 都能满血启动。
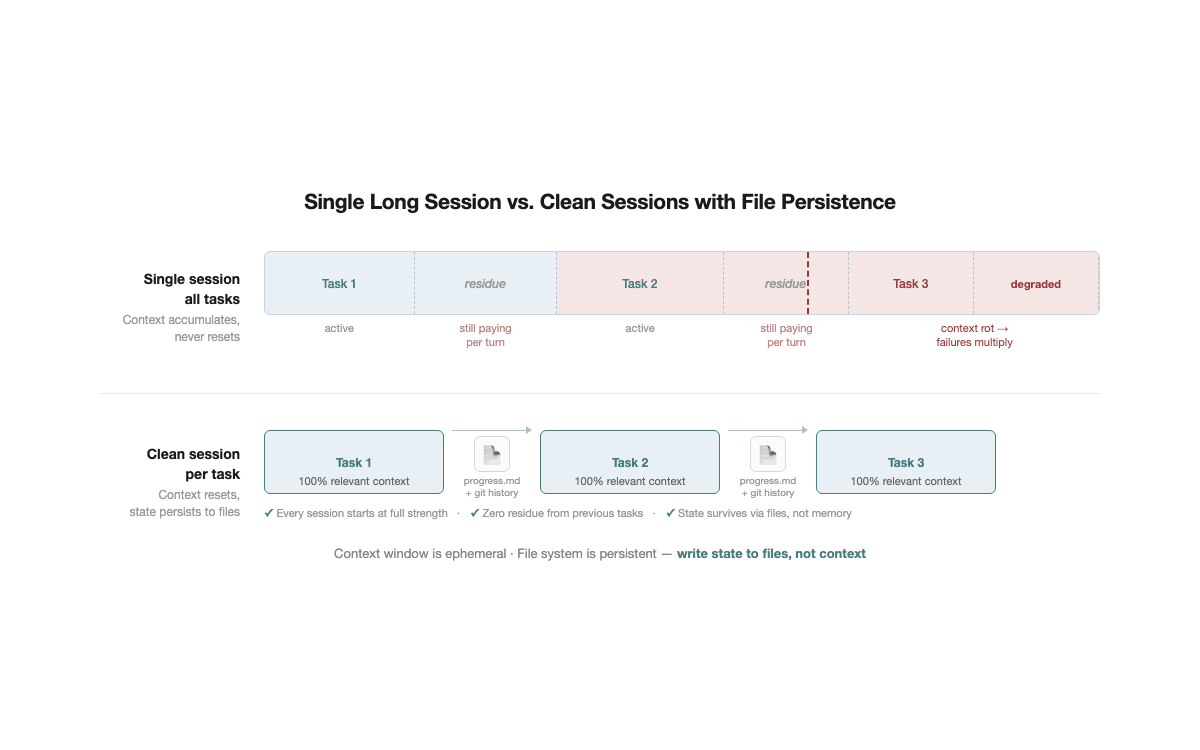
这是最低成本的质量提升手段。不需要任何工具,不需要改任何配置,今天就能开始做。
技巧 2:写好 CLAUDE.md
CLAUDE.md 解决的是项目级的持久化知识——编码规范、架构约定、工作流程。技巧 1 的 progress.md 是 GPS 定位,CLAUDE.md 是地图。
CLAUDE.md 本质上是你的 system prompt。但 system prompt 的影响力随对话变长而衰减——context 膨胀到 50K token 时,开头那段 CLAUDE.md 已经被大量 tool output 稀释了。所以每一行都要为 agent 的决策质量服务,不写废话,不写 agent 已经会的东西。
该写什么:
1. 项目结构地图(最高优先级)。 Agent 最大的时间浪费是"找不到东西"。tool output 占了 70-80% 的上下文,大量来自 agent 在项目里瞎找文件。只写 agent 无法从文件名推断的信息:
`markdown
- src/models/ — 推荐模型,核心是 ranking_model.py
- src/features/ — 特征工程,feature_config.yaml 定义所有特征
`
2. 工具选择决策树。 Agent 默认用 grep 全局搜索,效率极低。给锚定到可观察特征的指导:
找配置项,直接看 configs/、找特征定义,先看 feature_config.yaml。3. 项目特有的约定和陷阱。 Agent 不可能从代码推断:
embedding_dim 改了必须同步改 model_config.yaml。一条规则省一小时调试。Anthropic RL Engineering 团队的做法值得参考——CLAUDE.md 里只写具体的防错规则:run pytest not run、don't cd unnecessarily — just use the right path。不写空泛原则,只写 agent 真的会犯的错。4. 工作流程指令。 编码 planning/execution 分离:
涉及多文件修改:先列改动计划,确认后再执行。阻止 agent 改到一半发现冲突。不该写什么:
- 语言/框架通用知识。 Claude 已经知道,写了浪费 token,加速 attention decay。
- 过度详细的 API 文档。 CLAUDE.md 不是 reference manual。
- 空泛的原则。 "写高质量代码"对 agent 决策没有任何帮助。
- 历史变更日志。 不是 CHANGELOG,只保留当前有效的信息。
- 编码风格偏好。 Agent 对主流风格已经有很好的默认判断,逐条列偏好是低 ROI 的 context 开销。
- 重复已有配置。 pyproject.toml 里有的不用再写。
渐进式披露:分层加载,不要一次性堆砌。 CLAUDE.md 不是越长越好——每多一行,都在消耗 agent 处理当前任务的 context 空间。Anthropic 内部团队的实践(How Anthropic Teams Use Claude Code)揭示了一个共同模式:最有效的 CLAUDE.md 是分层的。
- 顶层 CLAUDE.md 只放入口级信息——项目结构、核心约定、关键路径。具体的工作流、详细的 API 用法、领域 playbook 拆到独立文件,CLAUDE.md 里用路径指向它们。Agent 需要时再读,不需要时不占 context
- 把重复指令封装成命令。 Anthropic Security Engineering 团队贡献了整个 monorepo 中 50% 的自定义 slash command——把频繁使用的工作流封装成命令,而不是写成长长的 CLAUDE.md 指令。命令只在调用时才加载,不用时零 context 开销
核心思路就像好的 API 设计——顶层简洁,细节按需展开。CLAUDE.md 是索引,不是百科全书。
组织原则: 控制在 200 行以内。高频信息放前面。用祈使句——"先看 xxx"而不是"建议先看 xxx"。可操作永远优先于可理解。
技巧 3:知道你的 Context 里装了什么
管理内存的前提是知道内存里有什么。
打开一个新 session,你的 context window 并不是空的。CLAUDE.md、MCP server 定义、已安装的插件和 skills、各种工具的 schema——这些在你发出第一条指令前就已经占据了 context 空间。用
/context 命令可以看到完整的初始 context 构成: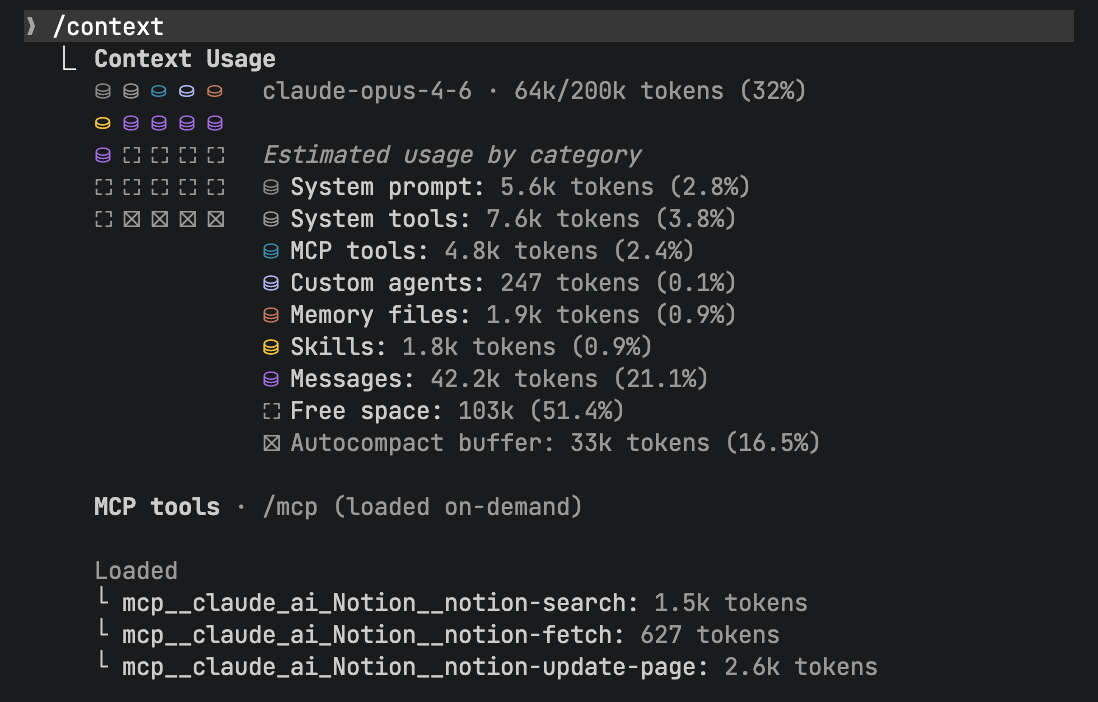
这很重要,因为 context 的有效容量不是名义上的 200K token。前面说过,超过 50% 性能就开始下降。如果初始化就占了 30%,你的有效工作空间只剩 20%——模型开始变笨的速度比你想象的快得多。
实操建议:
- 按需加载,不要预装。 每个 MCP server、每个插件、每个 skill 都会占用 context。十几个 MCP server 的工具定义可能就占掉上万 token。只装当前项目真正需要的,其余的按需启用
- 工具越多,干扰越大。 模型在每一步都要从所有可用工具中选择。无关的工具不只是浪费空间——它们是决策噪音,增加模型选错工具的概率
- 定期审计。 项目换了、工作流变了,但 MCP server 和插件往往只增不减。定期用
/context检查,清理不再需要的
这和技巧 2 的渐进式披露是同一个思路:不是信息越多越好,而是 agent 需要的信息越精准越好。每多一个 token 的初始占用,都在压缩后续的有效工作空间。
技巧 4:拆分 Task,每个极简
一个任务只做一件事。任务越大,context 越膨胀,失败率越高。
这不是直觉,是数据。根据 METR 对 agent 编码任务的基准测试,任务时间翻倍,失败率翻四倍。Context 膨胀是主因——工具输出、错误尝试、中间状态全部堆积,模型在自己制造的噪音里越陷越深。
所以核心思路不是"事后压缩 context",而是"任务本身就小到不需要压缩"。一个 2-5 分钟能完成的任务,context 根本来不及膨胀。agent 拿到干净的指令,做完一件事,交付,结束。
动态拆分优于静态拆分。 Anthropic 在 Building Effective Agents 中指出,coding 任务"你无法预测需要哪些子任务",推荐用 orchestrator 动态分解而非预定义流程。道理很简单:不要一次性规划 10 个子任务然后线性执行。如果第 2 步发现前提假设有误,第 3-10 步全部作废。更好的做法是:只规划下一步,完成后根据结果决定再下一步。每个子任务的输出是下一个子任务的输入条件——每一步都基于最新信息,而不是基于一个可能已经过时的计划。
举个例子。让 agent "给项目加用户认证",先进入 plan mode 探索——读依赖、查文档、评估方案,把计划写到 plan.md。第一步是集成 OAuth 库,做完发现库的 API 在最新版完全改了。如果是静态 10 步计划,后面 8 步全废。动态拆分下,agent 基于实际 API 重新规划下一步,每一步的输入都是上一步的真实产出,不是几分钟前的假设。
判断粒度的标准: 一个任务能不能用一两句话说清目标和验证条件?如果需要"然后……然后……然后……"才能描述,它太大了,拆。
自动化拆分: Superpowers 是一个开源的 Claude Code skills 框架,它把这个拆分流程固化成了可复用的 skill——自动把大任务拆成 2-5 分钟的 feature task,再派 sub-agent 独立执行每个子任务。你不需要手动拆,skill 替你拆。
技巧 5:Sub-agent 做 Context 隔离
技巧 1 说的是手动
/clear。Sub-agent 是它的自动化升级。机制很简单:主 agent 把一个子任务派给 sub-agent,sub-agent 在独立的 context window 里执行。几万 token 的探索——搜索文件、读代码、试错——最终压缩为 1000-2000 token 的结构化总结返回给主 agent。主 agent 的 context 始终干净。
你不需要手动判断"该 /clear 了",任务边界天然就是 context 边界。
Claude Code 内置三种 sub-agent:
- Explore(Haiku 模型): 只读。搜索代码库、定位文件、理解结构。成本低,速度快。
- Plan(继承主模型): 只读。分析问题、制定方案。用主模型的推理能力,但不动手改代码。
- General-purpose(全部工具): 可读可写。执行复杂的多步骤任务。
最佳实践: 读多写少的任务用 Explore 或 Plan,需要改代码的用 general-purpose。一个 sub-agent 一个明确目标,不超过 3-4 个。Sub-agent 不是越多越好——每个都有调度开销,拆太碎反而浪费。
你不需要手动派 sub-agent——很多命令已经帮你做了。 Claude Code 内置的
/simplify 就是一个例子:它自动派 sub-agent 审查你刚改过的代码,检查复用机会、代码质量和效率问题,然后在独立 context 里修复。你只需要一个斜杠命令,背后的 context 隔离、任务分派、结果汇总全部自动完成。类似的还有批量执行计划时的 sub-agent 调度——每个子任务一个独立 agent,做完返回摘要,主 agent 的 context 始终干净。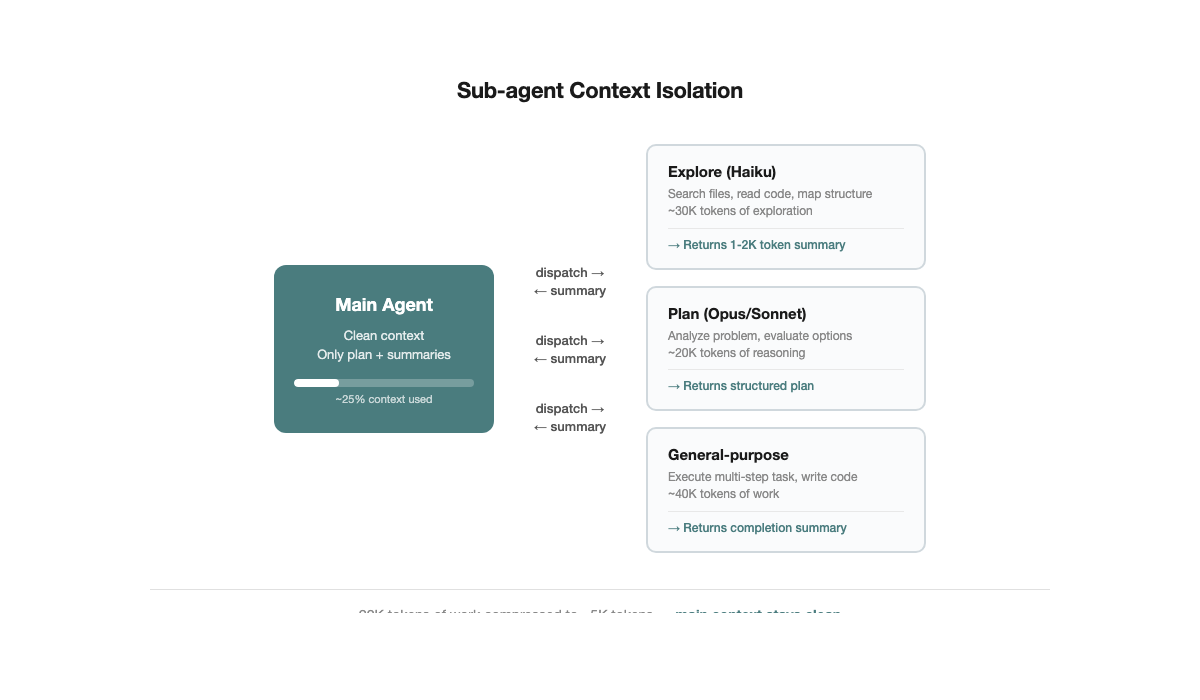
进阶用法:写者-审阅者分离。 一个 agent 写代码,完成后派一个独立的 sub-agent 做 review。Sub-agent 没有参与实现过程,context 里只有待审代码和项目规范——没有实现过程中的试错、没有设计权衡的心理包袱,天然没有确认偏差。这是 sub-agent context 隔离最直观的应用:写者和审阅者物理上就不共享 context,不需要靠自觉来保持客观。
技巧 6:用 Plan Mode 想清楚再动手
Claude Code 内置了 Plan Mode(快捷键 Shift+Tab 切换)。开启后,agent 只思考、不执行——搜代码、读文档、分析依赖,但不会写任何文件。
为什么需要 Plan Mode? 因为 agent 默认是"边想边做"——读到一半就开始改代码,改到一半发现方向不对,回滚,再试。每次试错都往 context 里塞几千 token 的工具输出。Plan Mode 把"想"和"做"分开:先充分探索,形成完整方案,再一次性执行。
怎么用:
- 进入 Plan Mode,描述目标。 比如"我要给这个项目加 OAuth 认证,帮我调研方案"。Agent 会搜索代码库、读依赖、评估选项,但不改任何文件
- 审查计划,确认后执行。 切回执行模式(再次 Shift+Tab),agent 按计划动手。方向已经确认,执行阶段很少走弯路
- 复杂任务:计划写到文件再执行。 如果探索阶段 context 已经很大,让 agent 把计划写到
plan.md,然后/clear,新 session 读 plan.md 执行。执行者的 context 里只有计划本身,没有探索过程的残留
核心价值: Plan Mode 是"先量后裁"。没有它,agent 经常"量一半就开始裁"——剪错了就得重来,浪费布料(context)。Plan Mode 确保 agent 在动手之前已经完整理解了问题,大幅减少执行阶段的试错和回滚。
给 Agent 设计 Harness
前六个技巧直接管 context——清 session 并持久化状态、写好 CLAUDE.md、审计初始 context、拆任务、用 sub-agent、Plan Mode。接下来换一个角度:不是手动管 context,而是用 harness(测试、hooks、代码质量、脚手架)来系统性地压住 context 爆炸。
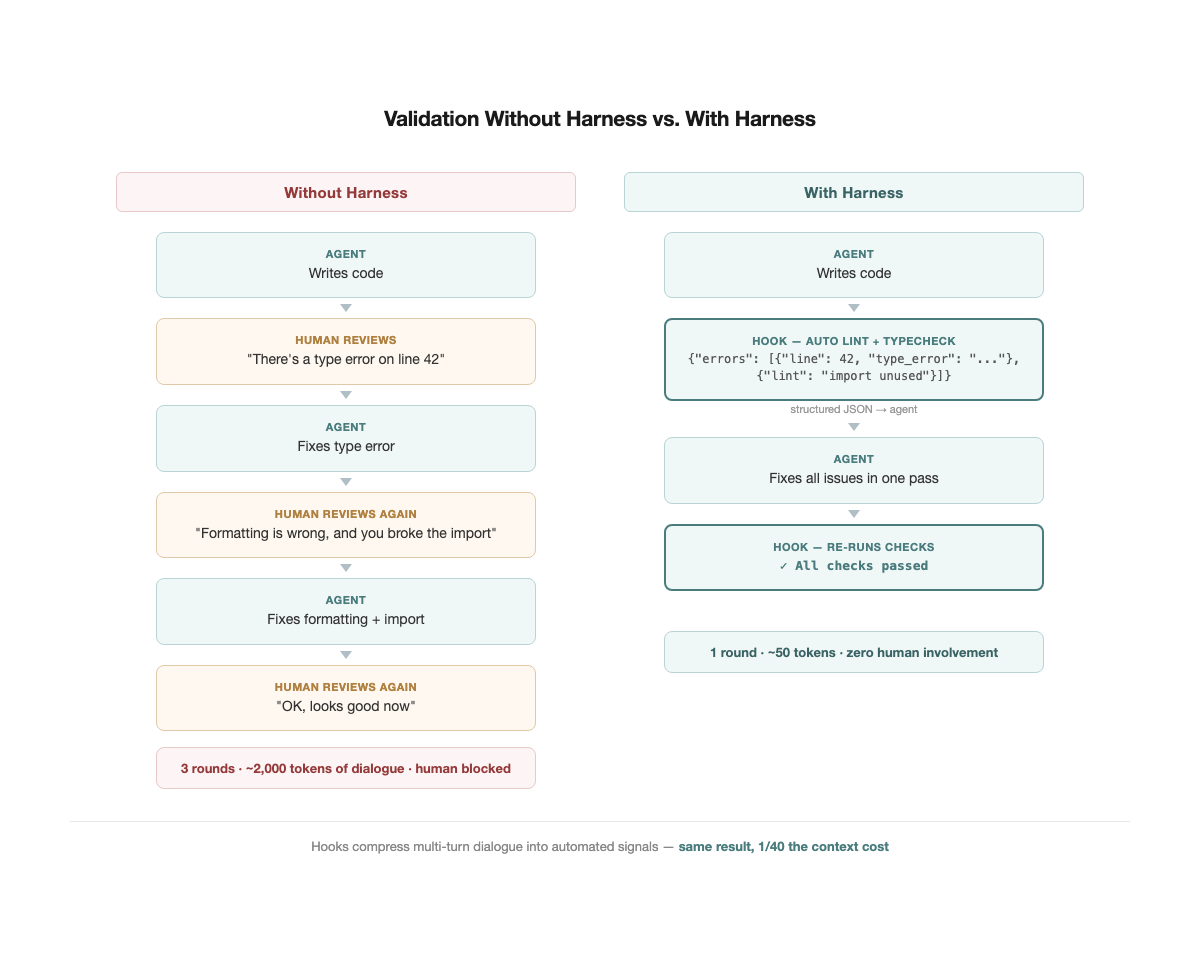
技巧 7:Red/Green TDD
没有测试的 agent 工作流是这样的:agent 写完代码,问你"这样对吗?"。你看一遍,说"不对,这里有问题"。它改,再问你。三轮下来,context 里塞满了几千 token 的来回对话——而这些对话本质上只传递了一个信号:对,或者不对。
测试把这个信号压缩到了极致。一个 pass/fail 只占几个 token,却比你用自然语言描述几百字更精准、更无歧义。
Simon Willison 在 Agentic Engineering Patterns 里专门写了 Red-Green TDD 模式。核心流程是三步:
- Red:先写会失败的测试。 让 agent 写测试,你花 30 秒扫一眼确认意图对了,跑一下确认是红的。这一步定义了"成功长什么样"。
- Green:让 agent 去实现,直到测试变绿。 Agent 有了明确的目标函数——不是"写一个好的实现"这种模糊指令,而是"让这 5 个测试通过"。
- 验证:确认测试确实是从红变绿的。 如果测试一开始就是绿的,说明测试本身有问题——它没有验证任何新行为。
为什么这个模式对 agent 特别重要?Willison 指出了两个 agent 特有的风险:写出不能用的代码,和写出没人用的代码。Red-Green TDD 同时解决这两个问题——测试定义了需要什么(防止多写),通过/失败验证了能不能用(防止写错)。
Tweag 的 Agentic Coding Handbook 给了更具体的工作流:先写测试,审测试,然后让 agent 去实现。 测试是需求的可执行版本——agent 不需要反复问你"是不是这个意思",跑一下就知道。
而且随着项目变大,测试的价值呈指数增长。每一次新改动都可能破坏已有功能,测试套件是唯一可靠的防线。没有测试的 agent 项目越做越脆弱;有测试的 agent 项目越做越稳固。
这回扣了全文的核心主题:context 是稀缺资源。没有测试,验证靠人肉对话,context 膨胀。有测试,验证自动完成,对话短,context 精简。TDD 不只是代码质量工具,它是 agent 最高效的自我验证机制——用最少的 token 传递最准确的反馈。
技巧 8:用 Hooks 做程序化反馈
TDD 解决了"代码行为对不对"。但还有一类问题更机械——类型错误、格式不规范、lint 警告。这些问题不需要测试来验证,但如果靠人肉对话来纠正,一样会膨胀 context。
Hooks 是确定性的自动反馈回路。 Claude Code 的 hooks 机制允许你在 agent 的关键动作(写文件、跑命令、提交代码)前后自动执行脚本。最典型的用法:PostToolUse hook 在每次文件编辑后自动跑 lint 和 typecheck,错误信息以结构化 JSON 直接返回给 agent。Agent 当场修复,不需要你说"这里类型不对"——零人肉对话,context 几乎不膨胀。
这和 TDD 是同一个逻辑的不同层面。TDD 验证行为正确性("功能对不对"),hooks 验证机械正确性("格式对不对、类型对不对")。两者都把本该靠人肉对话传递的信号压缩成了自动化的几个 token。
Hooks 还能做压缩善后。 前面说过,
/compact 会丢信息——这是 context rot 的另一种形式。社区里已经有成熟的方案:用 hook 检测到 compact 事件后,自动重新注入关键信息(比如重新读 progress.md、重新加载当前任务的上下文)。你不需要每次压缩后手动提醒 agent"刚才做到哪了",hook 替你做。实操建议:
- 最小起步: 一个 PostToolUse hook,在 Write/Edit 后跑
eslint或mypy,返回错误。这一个 hook 就能省掉大量格式和类型相关的对话
- 压缩善后: 用 hook 检测 compact 事件,自动注入"当前任务状态 + 已修改文件列表"。和技巧 1(progress.md)配合,压缩后也能快速恢复上下文
- Pre-commit 拦截: 在
git commit前自动跑测试,失败就阻断。Agent 不需要记住"提交前跑测试"这条规则——环境替它记
- 拦截危险命令: Agent 偶尔会跑出
rm -rf、git push --force、DROP TABLE这类破坏性操作——这不是理论风险,已经有开发者因此丢失整个 home 目录,Replit 的 AI agent 也曾在 code freeze 期间删掉了生产数据库。PreToolUse hook 可以在命令执行前做模式匹配,检测到危险命令直接阻断并返回警告
- 拦截卡死命令: 有些命令会让 agent 卡住(比如不带参数的交互式命令、等待输入的进程),哪怕偶然忘记一次就会浪费整个 session。用 hook 检测这类模式,直接拦截
核心思路:不要靠 agent 的记忆力,靠环境的确定性。Hook 是确定性的,每次都执行,不会因为 context 膨胀而被"忘掉"。
技巧 9:代码健康度直接决定 Agent 成功率

测试解决了验证问题。但还有一个更基础的因素:代码库本身的质量。
开头提到的那个三倍差距——健康代码上 agent 成功率 60%,烂代码上只有 20%——背后的原因就是 context rot。烂代码意味着更多隐式依赖、更长的函数、更模糊的接口。Agent 需要读更多文件才能理解上下文,走更多弯路才能找到正确的修改点。Context 膨胀,模型变笨,失败率上升。
这重新定义了技术债。过去我们说"技术债影响开发者体验",这是一个软性论述,很容易被业务优先级压下去。但现在技术债直接影响 AI 工具的 ROI——它变成了一个可量化的硬指标。你的代码健康度从 7 掉到 5,agent 成功率可能从 50% 掉到 20%。这不是代码洁癖,这是生产力损失。
CodeScene 的研究还发现,AI coding 不加约束时缺陷风险反而上升 30% 以上——agent 倾向于"搬移复杂度"而非真正简化。所以代码健康度不是一次性的,需要持续维护。
怎么做:
- 识别 Brain Method: 几百行的上帝函数——高圈复杂度、深嵌套、高耦合。这是 agent 失败率最高的地方。开一个专门的 session,让 agent 拆成小的内聚单元,每拆一个跑一次测试
- 每次 PR 前跑代码健康度检查: CodeScene 有 MCP Server 可以直接接入 Claude Code,也可以用 lint 规则控制函数长度和复杂度。关键是让"健康度下降"变成一个自动化的拦截信号,而不是靠人肉 review
- 重构和功能开发分开做: 不要在一个 session 里边加功能边重构。重构是一个独立任务——清 session、单独做、跑测试确认没破坏、提交。然后再开新 session 做功能
给 AI 一个干净的代码库,比给它更好的 prompt 更重要。
技巧 10:沉淀框架和脚手架,复用而非重复生成
代码健康度是被动的基础设施——保持代码库干净,agent 自然表现更好。但你还可以更主动:给 agent 造工具。
一个常见的浪费:每次让 agent 做类似的事,它都从头生成一套方案。生成本身消耗 context,生成的结果质量不稳定,而且你还得验证。如果同样的工作流你已经跑过三次,为什么不把验证过的版本固化下来?
核心逻辑: 把重复生成变成直接调用。Agent 调用一个现成的脚本,context 用量可能只有从头生成的 1/10,输出质量更稳定——因为工具本身已经被验证过了。
实操方式:
- 封装验证过的用法。 你的项目有一个 in-house 组件库,或者一套复杂的部署/发布命令。每次让 agent 用,它都得先读 API 文档、试错几轮才能搞对——每轮试错消耗几千 token。让 agent 把验证通过的用法封装成一个可复用的脚本或函数,下次直接调用,执行又快又省 context
- 把"怎么做"固化成工具。 任何你发现 agent 反复从头摸索的工作流——部署、发布、数据迁移——都值得变成一个能跑的脚本。不需要多完美,能跑就比每次重新生成靠谱
- Skills/Commands 系统: Claude Code 的 skills/commands 就是这个思路的产物——把工作流固化为可复用的命令,agent 直接执行
CLAUDE.md 和脚手架是一对搭档。CLAUDE.md 告诉 agent"用什么工具、遵守什么规则",脚手架是 agent 实际可以调用的工具。前者是说明书,后者是工具箱。
OpenAI Codex 团队总结过一个核心洞察:瓶颈从来不是 agent 写代码的能力,而是缺乏围绕它的结构、工具和反馈机制。这不是理论——他们 3 个工程师零手写代码,用 agent 产出了 100 万行代码、约 1500 个 PR,耗时约正常的 1/10。核心经验不是 prompt 写得好,而是 "When Codex got stuck, they treated it as an environment design problem." 给 agent 造好环境,比给它写好 prompt 重要得多。
从写代码到设计环境
这 10 个习惯归结到一句话:你的工作不再是写代码,而是设计一个让 agent 能高效工作的环境。管好 context,造好 harness——测试把人肉验证压缩成 pass/fail,hooks 把机械检查自动化,干净的代码库让 agent 少走弯路,脚手架把重复生成变成直接调用。
这些都不复杂。新 session、写文件、跑测试——没有一个需要搭建复杂系统。但绝大多数人不做。做了,就已经不一样了。