type
Post
status
Published
date
Mar 22, 2026
slug
from-next-one-to-next-n-zh
summary
推荐系统 20 年来方法换了六七轮,但问题定义从未改变——始终是预测下一个 item。缺多样性、缺发现性、规则泛滥,根源都在这里。真正的范式改变不是换方法,而是重新定义问题:从 Next One 到 Next N。
tags
推荐系统
技术趋势
思考
category
推荐系统
icon
password
priority
3
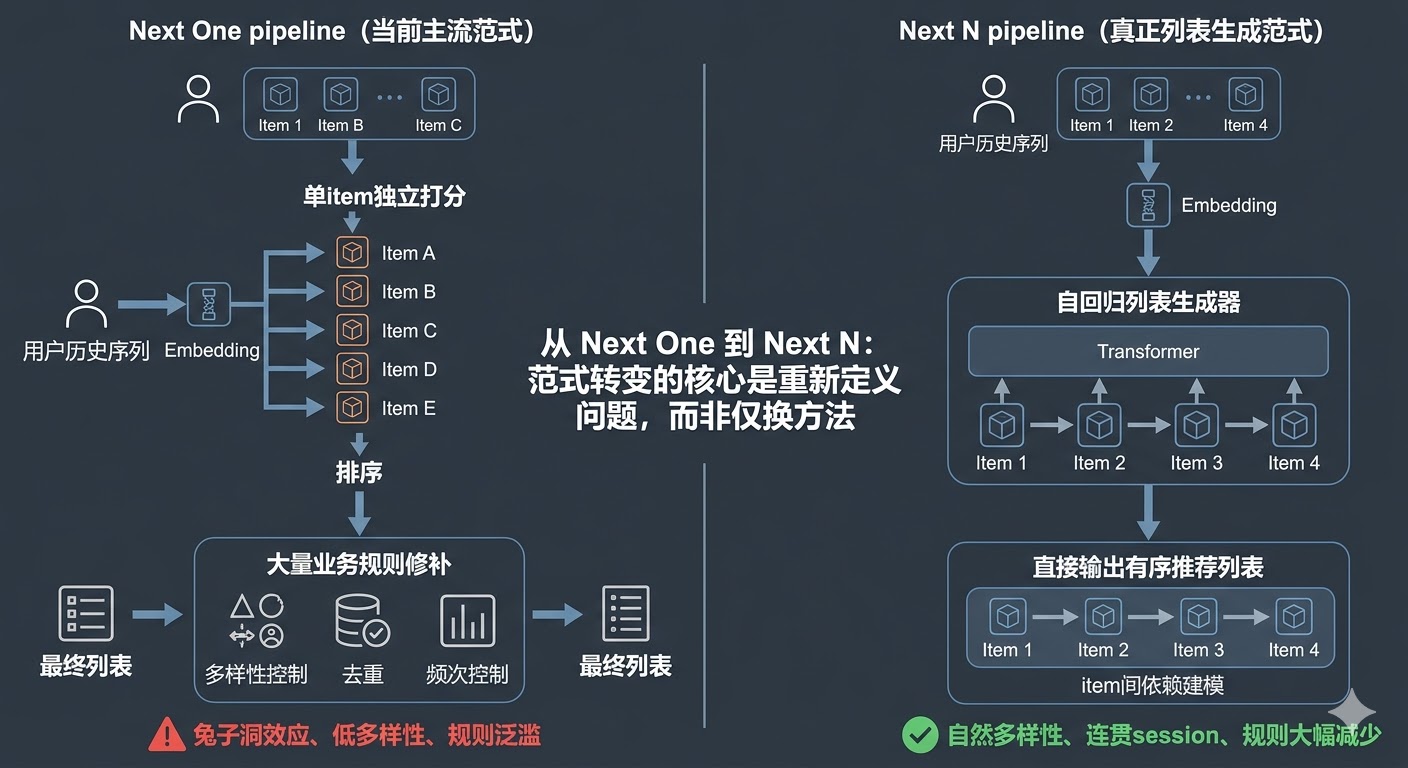
真正的范式改变,应该是推荐系统的问题定义:从 Next-One 到 Next-N,从预估下一个物品然后拼凑一个列表,到端到端生成一个列表。
从“矩阵填空”和“模型特征打分”,算是打分时代,怎么打分一个物品,推出一个列表,可以用 MMR+规则打散,弥补推出一个物品和一个列表的 GAP;推荐有了深度学习,有了 sequence 概念,问题的定义没变。“矩阵填空”升级到了“双塔”,突破“双塔”,生成式;模型打分加上了复杂模型交叉,sequence 建模,模型参数Scaling Up。但始终还是在做打分,在一条时间线的样本上做 Next-One 预估。所以,你实际系统系的规则一点不少,多样性/新颖新还要靠额外的模块保障,类 MMR 方法还在,或者只是加了个号称 list-wise 的重排模块。
Next-One 怎么理解?如果有一条时间线,上面包含了所有系统曝光和用用户反馈,从任意时间切一刀竖线,现在推荐系统的绝大多数算力花在了利用这个竖线之前的数据,预估竖线后下一个物品是什么和打多少分。
也许有模块是并非是这样的设计(比如 LTV 预估),但召回排序作为推荐系统的核心算力是 Next-One 的,而其他的模块——多样性/发现性/长期价值/去重规则/打散规则/重排模块/delayed feedback几乎是核心算力在做 Next-One 的补丁包。
这样的问题定义,哪怕方法 Scaling Up 到极致,它都无法产生智能的推荐系统。
1. 历史回顾——Next One 是怎么被锁死的
1.1 问题定义的起点(2001-2009)
推荐系统的问题定义从第一天起就是 Next One。
Linden et al.(2003) 发表 Amazon item-based CF——计算 item-item 相似度,对每个候选 item 逐个打分,推最高分的。这是最早被大规模使用的推荐算法,它的输出单位就是一个 item 的分数。
然后是 Netflix Prize(2006-2009)。这场历时 3 年、奖金 100 万美元的竞赛把推荐系统研究推向了主流。但它的评测指标是 RMSE——优化的是 (user, movie) pair 的评分误差,一次预测一个评分。BellKor 团队最终以 RMSE 0.8567 赢得比赛,比 Netflix 自己的 Cinematch 系统提升了 10.06%。获胜方案的核心?更好地预测单个评分。
Koren et al.(2009) 将 Netflix Prize 的经验系统化,发表了矩阵分解的经典论文。数学形式很清晰:r̂(u,i) = qᵢᵀ · pᵤ——用户向量和 item 向量做内积,输出一个数字。填矩阵的一个格子。这就是 Next One 最纯粹的数学形式。
同年,Rendle et al.(2009) 提出 BPR(Bayesian Personalized Ranking),用 pairwise loss 替代 pointwise loss——优化的是 item 之间的偏序关系。这是损失函数层面的进步。但输出呢?还是每个 item 一个分数。
2009 年,矩阵分解和 BPR 几乎同时确立了推荐系统的基本范式:不管你用什么方法训练,最终输出都是对单个 item 的打分。这个范式此后 17 年没有变过。
1.2 评测与问题定义的共谋
问题定义已经被锁死了,从评测中可见一斑。
Leave-one-out 评测:从用户的交互历史中留出最后一个 item,让模型预测。问题被硬编码成"猜这一个"。He et al.(2017) 的 NCF 论文用了这个方案,此后几乎所有序列推荐论文都 follow 了同样的设置——因为这样最容易和 NCF 比较。
AUC:评估的就是一个 positive sample 在排序中的位置——模型能不能把这"一个"正样本排在负样本前面。连评价的单位都是一个 pair。
HR@K(Hit Rate at K):唯一的正确答案在不在 top K 里?这是最纯粹的 Next One 指标。模型只需要把那"一个"正确 item 排进前 K 就算赢。
NDCG@K:看起来在评价列表质量,实际评价的是 pointwise 分数排序的产物。10 个同类 item 的列表和 10 个多样化 item 的列表,NDCG 完全相同——因为 NDCG 不关心 item 之间的关系,只关心每个 item 的相关性等级。
Top-K 推荐的定义陷阱:表面上推荐 K 个 item,实际是 K 次独立的 Next One。每个 item 的分数独立计算,K 个 item 之间没有交互建模。排第 1 的 item 不知道排第 2 的是什么。
数据集也在加固这个循环。MovieLens、Amazon Reviews、Yelp——学术界最常用的三个数据集,原子单位都是单次 (user, item) 交互。没有"展示了什么但用户没点"的信息,没有列表上下文,没有 session 结构。数据记录的就是 Next One,模型能学到的也只能是 Next One。
这是一个自我强化的循环:数据集记录单次交互,评测留一个,模型优化单项得分,论文刷 SOTA,新数据集继续记录单次交互。20 年来,这个循环从未被打破。Aixin Sun(2022) 的评测综述尖锐地指出了这些问题,但行业惯性太大——大家还是在用同样的数据集、同样的评测、同样的问题定义发论文。
1.3 Ranking 的演进:方法升级,问题不变
方法每 2-3 年换一轮,问题定义纹丝不动。
召回侧:MF 升级到双塔,本质没变——两个向量做点积,输出一个 item 的分数。
排序侧:从 LR + GBDT 到 Wide & Deep,再到 DIN/DIEN,再到多目标。每一轮方法升级,输出都是一个 item 的分数。DIN 用 attention 关注和"当前候选 item"相关的历史行为——"当前候选 item"这几个字说明一切。
工业 pipeline 固化:4 阶段 cascade(召回、粗排、精排、重排)在 2016-2020 年逐步定型。每一阶段做同一件事:对单个 item 打分,排序,截断。COLD(Alibaba, 2020) 优化的是"怎么更高效地给每个 item 打分"。整个 pipeline 的架构假设就是:推荐 = 打分 + 排序。
1.4 Listwise Learning:看起来 Next N,实际 Next One
有一类方法看起来在做 Next N。实际上没有。
ListNet(Cao et al., 2007) 首次引入了 listwise 损失函数。它的损失函数确实是在列表层面计算的——用排列概率分布之间的 KL 散度。但看模型本身:对每个 item 独立计算 score f(xⱼ),然后把这些独立的 scores 收集起来做 softmax。
本质是什么?Pointwise 的 score function + listwise 的 loss function。预测时每个 item 依赖的特征仅仅是它自己——item A 的分数不知道 item B 的存在。ListMLE(2008)同理。
10 年后,DLCM(Ai et al., 2018) 和 PRM(Pei et al., 2019) 在重排阶段用 RNN/Transformer 建模 item 间交互——这是真正的进步。但输出呢?还是对每个 item 重新打分。PRM 的论文写得很清楚:Score(i) = softmax(F⁽ᴺˣ⁾ · Wᶠ + bᶠ)——Transformer 编码了 item 交互信息,但最终还是产出 N 个独立分数。
编码了 item 交互不等于生成了列表。这些工作在打分函数层面引入了 item 间的信息,但输出单位没变——还是一个 item 一个分数。
1.5 YouTube 的影响:问题定义如何扩散到整个行业
YouTube DNN(Covington et al., 2016) 是 2016-2020 年工业推荐系统的标杆。几乎每个做推荐的团队都读过这篇论文,很多团队直接照着它搭系统。
它固化了什么?两件事:
- 召回 = 超大规模分类:从几百万视频里分类出用户下一个会看哪一个——"which ONE video?"。论文原文:"We pose recommendation as extreme multiclass classification where the prediction problem becomes accurately classifying a specific video watch wₜ."
- 排序 = per-video 预测:对每个候选视频独立预测观看时长
YouTube 的推荐体验怎么样?发现性差,多样性一般。"兔子洞"效应(rabbit hole)被大量用户和媒体讨论——你看了一个关于某主题的视频,接下来满屏都是同类内容。这不是 bug,这是 Next One 的必然结果。当模型只回答"下一个最可能点击的视频是什么"时,它当然收敛到用户历史的局部最优。
整个行业 follow 了 YouTube 的方法——双塔召回、多阶段 cascade、per-item 排序。也 follow 了它的问题定义。以及它的局限。
2. 规则是 Next One 的补丁
2.1 规则泛滥与重排的修补
一个典型的工业推荐系统里,重排阶段的业务规则可以有几十到上百条。多样性规则、去重规则、频控规则、新鲜度规则、品类配额规则——它们在修复同一个问题:模型只会给单个 item 打分,无法生成"好的列表"。
例子很简单。两个美食视频 CTR 都是 0.95,排序模型把它们排在第 1 和第 2。用户看到连续两个美食视频,划走了。于是产品经理加一条规则:"同品类内容间隔至少 2 个位置。"又过两周,连续出现两个同一作者的视频,再加一条:"同作者内容不超过 2 个。"规则就这样一条条长出来。
这些规则不是在解决新问题,是在给 Next One 打补丁。模型不知道列表里还有什么——它给每个 item 独立打分,打完就结束了。列表的多样性、节奏感、品类分布,全部交给规则来收拾。
学术界不是没注意到这个问题。重排阶段的几乎所有经典方法,都在试图修复 Next One 留下的烂摊子。但它们的修复方式,本身还是 Next One。
- MMR(1998):贪心算法。循环里每步选一个 item,最大化"和已选 item 不同 + 和 query 相关"的加权和。每步是一次 Next One——选当前最优的那一个
- DPP(Determinantal Point Process):MAP 推断是 NP-hard,实际用贪心近似——逐个选,和 MMR 一样
- Seq2Slate(Google, 2019):pointer network 逐步从候选集中选 item,每步的选择依赖前面已选的 item。这其实是一个正向的尝试——它在向 Next N 靠近。但 Seq2Slate 在工业界并没有流行起来,实际部署的案例很少
MMR 和 DPP 有一个共同点:在精排打完分后,对几十个候选做微调。算力占比极小——整个推荐 pipeline 99%+ 的算力花在召回和精排上,重排只处理精排留下的几十到几百个 item。解空间也极小。
2.3 GE 框架:解空间有多小
Generator-Evaluator(GE)框架 是重排阶段一种常见的范式。思路很直观:Generator 产出若干条候选列表,Evaluator 从中选最好的一条。
Generator 的来源通常是 Beam Search、规则组合、MMR 的不同参数设置——产出几十条候选列表。Evaluator 对每条列表打分,选分数最高的。
解空间有多大?50 个候选 item 选 10 个组成列表(考虑顺序),理论组合数约 P(50,10) ≈ 10¹⁶。Generator 看了几十种。覆盖率约 10⁻¹⁵——这不是近似,这是没看。
这就是 Next One 的代价。因为模型只会打 pointwise 分数,列表生成这件事只能用启发式规则和小规模搜索来凑合。真正需要做的——在 10¹⁶ 量级的组合空间里找到好的列表——被完全放弃了。
3. 生成式推荐是不是未来?取决于你在问什么问题
3.1 "生成式推荐是不是未来的范式?"
这是过去两年推荐系统社区讨论最多的问题之一。生成式 AI 爆火,GPT / LLM 证明了 Transformer 自回归 Decoder 的威力——推荐系统能不能也用这个范式?
一系列工作迅速把推荐系统的组件和大模型对应起来:item 变成 token(Semantic ID),用户行为序列变成 input sequence,推荐变成 next token prediction。看起来很有希望。
但问题定义没变。
用 Transformer 替代双塔,用 NTP 替代 softmax,用 Semantic ID 替代 item embedding——方法全换了,但模型还是在回答同一个问题:"下一个 item 是什么?"
方法的改变不是范式的改变。真正的范式改变,从问题的重新定义开始。
3.2 各家的"生成式",还是在做 Next One
挨个看。
- TIGER(Google, 2023):用 RQ-VAE 给每个 item 生成 Semantic ID(一个多 token 元组),训练 Transformer 自回归解码下一个 item 的 Semantic ID。论文原文:"the recommender system's task is to predict the next item"。Beam Search 产出多个候选——但每个候选是一个 item,不是一个 list。多个候选 = 同一次预测的不同假设,不是联合生成的列表
- OneRec(快手, 2025):统一召回和排序的端到端生成式推荐,用 Semantic ID + encoder-decoder + MoE 做自回归生成。快手主站部署,watch-time +1.6%。但生成的还是一个 item 的 Semantic ID——多 token 解码出一个 item
- HSTU(Meta, 2024):万亿参数级生成式推荐,把推荐问题建模为序列转导任务。Meta 多个产品线部署,线上指标 +12.4%。同样的问题——生成的单位还是 next item
- 39+ 篇 Semantic ID 论文(2025-2026):几乎全在研究同一件事——怎么更好地生成一个 item 的 ID。更好的量化方法、更好的码本结、更好的训练策略
这些工作有价值——它们在召回效率、表征学习、跨模态对齐上都有推进。但本质是用新方法做老问题。方法从矩阵分解换成了自回归 Decoder,问题还是 Next One。
3.3 Beam Search 不等于 Next N
这个误解值得单独拆解。
生成式推荐的概率建模是:P(tokenₜ | token₁, ..., tokenₜ₋₁, user_history)——每步预测下一个 token。多个 token 组成一个 item 的 Semantic ID。item 内部是自回归的——第 2 个 token 依赖第 1 个。但 item 之间呢?没有依赖。模型生成完一个 item 的 ID 就结束了,下一个 item 的生成和上一个无关。
Beam Search 在这里做的事情是:在生成一个 item ID 的过程中保留多个候选路径,最终输出 K 个最可能的 item。这不是"生成 K 个 item 的列表",这是"对同一个问题给出 K 个答案"。
类比:GPT 用 Beam Search 生成 5 个 response candidate,没有人会说这是"Next 5 Response"。这是对同一个 prompt 的 5 种可能回答,不是一个包含 5 段内容的连贯序列。推荐领域也一样——Beam Search 产出 5 个候选 item ≠ 生成了一个 5-item 的推荐列表。
所以区分 Next One 和 Next N 不需要看用了什么方法——协同过滤、深度学习、Transformer、扩散模型都无所谓。只需要问一个问题:
模型在回答什么问题?
- Next One:给定用户历史,预测/生成下一个最可能的 item。输出单位是 item
- Next N:给定用户历史,直接输出推荐列表。item 之间联合生成,第 3 个 item 的选择依赖前 2 个。输出单位是 list
生成式推荐是不是未来?取决于它在生成什么——一个 item,还是一个 list。如果还是一个 item,那不管用了多先进的方法,问题定义没变,范式没变。
4. 我对 Next N 的追求
4.1 最初的直觉
我刚开始做推荐系统的时候,就觉得哪里不对。
优化目标是 CTR——每个 item 的点击率。但用户体验的不是单个 item,是一整个列表,一整个 session。你可以让列表里每个 item 的 CTR 都很高,但用户刷了三屏全是同类内容,关掉 App 走了。单个 item 最优不等于列表最优——这个直觉很强,但当时没有工具来验证它。
CF、CTR 预估、Ranking Model——所有工具的输出都是一个 item 一个分数。你没法"生成"一个列表,只能给每个 item 打分然后排序。想做 Next N,手上的武器全是 Next One 的。
在淘宝的一个小场景上,我们把排序模型的 CTR 优化得更好了。但线上数据让人意外——浏览深度从约 28 降到约 21,session 平均点击数从约 2.08 降到约 2.04。CTR 更高,但用户走得更快了。
原因不难理解。模型被训练成"找到最可能被点的 item",它就把最可能被点的全堆上去。用户连续看到同质内容,很快腻了,提前离开 session。CTR 上去了,session 的总点击数反而下降了。
这不是 feature engineering 的问题,是问题定义的问题。优化单个 item 的点击率,和优化用户整个 session 的体验——这是两个不同的问题,有时候答案恰好相反。
于是我们提出了 CTE(Click-Through quantity Expectation),把用户离开概率建模进优化目标——不只看"这个 item 会不会被点",还看"推了这个 item 之后用户会不会继续留下来"。这本质上是一个生成式的排序模型:用 RL(REINFORCE)做策略优化,Simulation Environment 充当 reward model,优化目标是 session 的总收益。每次生成一个物品,多轮 decode,每步选 item 时知道前面选了什么。
线上 A/B 结果:
- session 平均点击数(AC):+6.22%
- 浏览深度(AD):+4.92%
- 品类覆盖度和多样性也自然提升——没有加任何多样性规则
最后一点最关键。多样性不是靠规则强行注入的,是模型自己学到的——因为它在优化 session 整体的点击量,而不是单个 item 的 CTR。当优化目标对了,多样性是自然的副产品。CTR is not Enough 记录了完整的实验。
4.2 问题定义已经清楚了,局限在于工具
这篇论文投稿时被拒了。审稿人最大的质疑是:在如此巨大的动作空间里,怎么让 RL work?
今天回头看,这个质疑本身就是基于原有经验的拒绝——审稿人在用 Next One 时代的认知框架来判断一个 Next N 的问题。大模型在词序列上做 next token prediction,vocabulary 几万到几十万,序列长度几千到几万——这个动作空间比推荐列表生成大得多,而且完全 work。问题定义其实已经想清楚了:优化目标应该是 session 级别的,模型应该生成列表而不是打分排序。当时真正的局限在于算力——policy network 用的是 RNN,虽然 reward model 已经用了 Transformer Encoder,但整体规模受限于 GPU 算力。缺的不是想法,是工具。今天条件成熟了。
方法可以不同——RL、自回归 Decoder、Diffusion、CVAE——都无所谓。但问题定义必须变。从"预测下一个最可能的 item"到"生成一个好的推荐列表"。从 Next One 到 Next N。这才是范式的改变。方法是手段,问题定义才是方向。
5. 什么是真正的 Next N
5.1 Next N 的定义与意义
最纯粹的 Next N:输入用户历史行为序列,直接输出推荐列表。模型的输出单位是 list,不是 item。
数学上的区别很清晰:
- Next One:∏ P(itemᵢ | user_history)——N 个独立概率的乘积。每个 item 的分数独立计算,item 之间互不知情
- Next N:P(item₁, item₂, ..., itemₙ | user_history)——联合概率。第 3 个 item 的选择条件包含前 2 个 item
联合概率 vs 独立概率的乘积——前者可以建模 item 间的依赖关系,后者不能。这是本质区别。
Next One 的问题是:用户感知的是一个列表,但模型优化的是单个 item。模型在逐个打分而不是在生成列表,它的输出不可能和用户对推荐的感知一致,智能程度被问题定义卡住了上限。缺多样性、缺发现性、规则泛滥——都是这个错位的下游症状。而规则的引入不但没有解决这个问题,反而进一步固化了上限——规则是人写的,人能写的规则数量和质量是有天花板的。
Next N 直接消除这个根源:生成第 3 个 item 时知道前 2 个是什么,优化的是列表整体的用户满意度。多样性、发现性成为模型自然学到的属性,那些补丁式的业务规则也不再需要。
5.3 自回归 Decoder:Next N 所需的机制已被证明可行
这里需要一个关键区分——因为第 3 章讲过,自回归生成式推荐大多还是 Next One。区别在哪?
- 自回归生成一个 item 的多 token ID:token 之间有依赖,但生成目标是一个 item。多个 token 拼成一个 Semantic ID,对应一个 item。这是 Next One
- 自回归生成列表中的多个 item:item 之间有依赖,每个 item 的选择条件包含前面已选的 item。生成目标是一个 list。这是 Next N
生成的单位是区别所在。 不是"有没有用自回归",而是"自回归在生成什么"。
大模型证明了后者的机制可以 work。输入一个 prompt,输出一个连贯的序列——序列内部有结构、有多样性、有节奏。每个 token 的生成依赖所有前文。GPT 不会生成 5 段一模一样的文字,因为它在生成第 3 段时知道前 2 段写了什么。
推荐需要同样的东西。类比:
- 用户行为序列,类比 prompt
- 推荐 item 序列,类比 response
LLM 的 vocabulary 几万到几十万,序列长度几千到几万。推荐列表?item 池百万级,但列表长度通常 10-30。在机制层面,大模型已经在一个更大的动作空间里证明了这件事可以做。
5.4 算力时代已经来临
低算力时代,把列表生成简化为 N 次独立的 item 打分——这是合理的工程 trade-off。算不起联合概率,就用独立概率的乘积来近似。但今天条件变了。
之前困扰 Next N 的工程挑战——解空间爆炸、训练信号稀疏、推理延迟——正在因为大模型技术的进步而逐步消解。Semantic ID 压缩了解空间,RLHF 提供了 list-level 反馈机制的范式,投机采样 和 KV cache 在持续优化推理速度。这些不再是不可逾越的障碍。
而且算力成本还在加速下降。每 FLOPS 的计算成本符合莱特定律——累计产量每翻一倍,成本下降固定比例。明年 NVIDIA Rubin 架构还会让推理算力再翻几倍。今天觉得"算不起"的列表生成,两三年后可能和今天的 pointwise 打分一样廉价。
问题定义修正好之后,剩下的是大家集体的投入。
6. Paper is cheap, show me the system
论文不缺。学术界已经有一系列工作在探索列表级生成。但论文发了不等于系统落地了——我们完全不知道这些工作有没有真正跑在线上、跑了多久、占了多少算力。Paper is cheap, show me the system。
6.1 算力分配是检验标准
怎么判断一个系统是否真正落地了 Next N?算力分配是检验标准。
这是我个人的标准:如果一个系统里超过 50% 的算力分配给了列表生成而不是单 item 打分——我愿称它为业界最强。
今天即使最激进的系统,这个比例恐怕不到 20%。50% 意味着一个范式跃迁。
现实是什么?即使最有野心的实践——PRS、JDRec——列表级优化也只发生在重排阶段,对几十个候选做微调。召回和排序占据 90% 以上的算力,而它们还是纯 Next One。
SlateQ(Google/YouTube, 2019) 是一个标志性的案例。Google 试图用 RL 优化 slate 的长期价值——直接建模列表级 Q 值。结果呢?组合爆炸。最终他们证明:必须把 slate 的长期价值分解为单 item 的 LTV 之和,才能在 YouTube 的规模下运行。换句话说,即使 Google,也不得不把 Next N 的问题退化回 Next One 才能上线。
再看第 2 章分析的 GE 框架——覆盖率 10⁻¹⁵,与其说是列表生成,不如说是列表抽签。
6.2 为什么这么难
原因不复杂:整个工业基础设施围绕 Next One 建设了 20 年。
- 架构假设:4 阶段 cascade 的每一环都假设推荐 = 打分 + 排序。要做 Next N,不是改一个模块,是改整个 pipeline
- 训练数据:记录的是 item-level 反馈。没有"这个列表整体好不好"的标注。训练信号的粒度决定了模型的粒度
- 组织惯性:召回团队优化召回率,排序团队优化 AUC,重排团队写规则。每个团队的 KPI 都是 Next One 的指标。改问题定义意味着改组织结构
- 算力不足:Next-N 需要更大的算力,来处理负责的物品组合空间。
Next-One 发展到极致,就是流式推荐。在一个时间线上,迫切地要用下一个能观察到的反馈更新模型,也就是这个模型的更新发生在未来还不明朗的当下,我们观察到“一点点未来”就急着更新模型了!
它确实非常有效,它追求模型能“记录下”的信息的时效性,哪怕简单的记忆性特征也可以打败复杂的泛化模块。但同时,它也锁住了问题定义,追求泛化性和 Next-N 需要在一两个绩效周期里做到超越20 年算法和基建发展的水平,当然困难。
但现在 LLM 给出了一套模板,给了我们信心。应该在更高的上限的问题定义下重塑推荐系统,Scaling Limit 比 Scaling ROI 重要。
而工程的难度和算力问题。大模型也曾面对同样类型的问题——靠的是 KV cache、投机解码、量化、分布式推理。推荐系统的列表生成规模更小(10-30 个 item vs 几千到几万个 token),没有理由认为这些工程问题不可解。难的不只是技术,还有惯性。
结尾
20 年来方法换了六七轮,问题定义没变。生成式推荐用新方法做老问题,不是范式改变。真正的 Next N 是输入行为序列、输出推荐列表、item 联合生成。算力时代已经来临,评测和数据集也要跟着变——从评价"猜中了哪一个"到评价"这个列表整体好不好"。
下次有人讨论"生成式推荐是不是未来",先问一个问题:它在生成什么——一个 item,还是一个 list?
如果答案是一个 item,那方法变了,问题没变,范式没变。
推荐系统的下一个突破,不会来自更好的 Next One,而是来自重新定义问题——From Next One to Next N。