type
Post
status
Published
date
Mar 14, 2026 05:51
slug
rec-weekly-2026-W11
summary
2026 年第 11 周(3 月 8-14 日),推荐系统研究呈现两条清晰的技术主线。第一,生成式推荐(GR)正在经历从"能跑起来"到"跑得好、跑得快、跑得对"的全栈优化——Netflix/Meta 的指数奖励加权 SFT 解决后训练对齐、LinkedIn 的因果注意力重构将序列长度减半、快手的 FP8 量化将 OneRec-V2 推理延迟降低 49%、阿里的可微几何索引从根源消除长尾偏差,五篇论文从五个维度推进 GR 范式的工业级成熟。第二,LLM 推荐正在从"单次推理出结果"走向 Agent 化范式——Meta 的 VRec 在推理链中插入验证环节、美团的 RecPilot 用多 Agent 框架替代传统推荐列表、中科大的 TriRec 首次引入三方协调、人大/京东的 RecThinker 实现自主工具调用。
表示学习方面同样活跃。华为的 RF-Mem 将认知科学双过程理论引入检索管线,Amazon 的 P²GNN 用原型集增强 GNN 消息传递并在 18 个数据集排名第一,另有工作探索直接从 LLM 隐藏状态提取检索嵌入。此外,联邦推荐、机器遗忘和隐私合规方向也出现了多篇值得关注的工作,指向推荐系统基础设施级的隐私需求正在快速成熟。
tags
推荐系统
周报
论文
category
推荐技术报告
icon
password
priority
本周概览
2026 年第 11 周(3 月 8-14 日),推荐系统研究呈现两条清晰的技术主线。第一,生成式推荐(GR)正在经历从"能跑起来"到"跑得好、跑得快、跑得对"的全栈优化——Netflix/Meta 的指数奖励加权 SFT 解决后训练对齐、LinkedIn 的因果注意力重构将序列长度减半、快手的 FP8 量化将 OneRec-V2 推理延迟降低 49%、阿里的可微几何索引从根源消除长尾偏差,五篇论文从五个维度推进 GR 范式的工业级成熟。第二,LLM 推荐正在从"单次推理出结果"走向 Agent 化范式——Meta 的 VRec 在推理链中插入验证环节、美团的 RecPilot 用多 Agent 框架替代传统推荐列表、中科大的 TriRec 首次引入三方协调、人大/京东的 RecThinker 实现自主工具调用。
表示学习方面同样活跃。华为的 RF-Mem 将认知科学双过程理论引入检索管线,Amazon 的 P²GNN 用原型集增强 GNN 消息传递并在 18 个数据集排名第一,另有工作探索直接从 LLM 隐藏状态提取检索嵌入。此外,联邦推荐、机器遗忘和隐私合规方向也出现了多篇值得关注的工作,指向推荐系统基础设施级的隐私需求正在快速成熟。
生成式推荐的架构与后训练优化
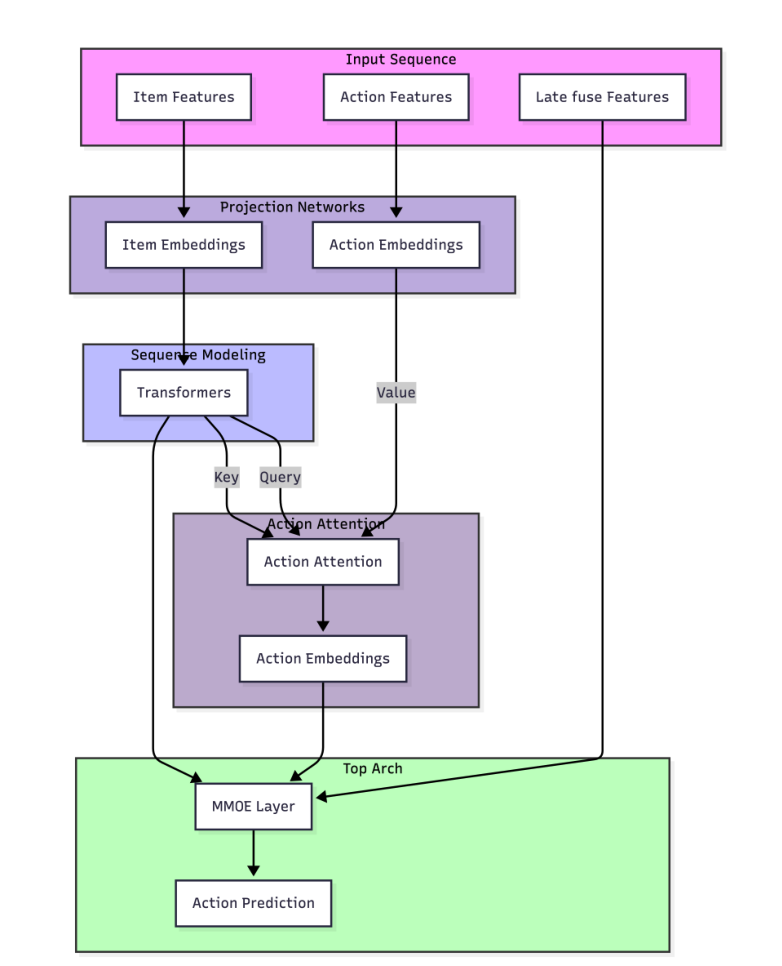
生成式推荐正在经历从概念验证到工业落地的关键转型。自 HSTU 确立 GR 范式以来,核心挑战已从"如何用 Transformer 建模序列"转向系统级的全栈优化。本周五篇论文分别从后训练对齐、因果注意力重构、推理量化、RL 微调和端到端索引五个维度推进这一方向。
Robust Post-Training for Generative Recommenders (2603.10279)
Netflix 和 Meta 联合提出的这篇工作直击 GR 后训练的核心痛点:RLHF 在推荐场景下容易 reward hack,离线 RL 需要不可得的 propensity score,在线交互在生产环境中不可行。他们的方案出人意料地简洁——指数奖励加权 SFT,权重公式仅为 $w = \exp(r/\lambda)$。理论上,该方法在噪声奖励下的策略改进保证,gap 仅随 catalog size 对数增长;实践上,温度参数 $\lambda$ 提供了鲁棒性与改进之间可量化的 tradeoff 控制。在三个开源数据集和一个私有数据集上,该方法一致性地优于 DPO、IPO、KTO 等 RLHF 变体。
值得注意的是,论文明确以 SASRec、HSTU 和 OneRec 作为基础架构进行扩展验证。OneRec-V2 采用的 Duration-Aware Reward Shaping 和 Adaptive Ratio Clipping 属于另一条偏好对齐路径,而本文用更轻量的方式达到了可比甚至更优的效果——对工业落地有直接参考价值。
Beyond Interleaving: Causal Attention Reformulations for Generative Recommender Systems (2603.10369)
LinkedIn 这篇工作对 GR 的序列建模方式做了一次根本性反思。当前主流 GR(如 Meta 的 HSTU)将 item token 和 action token 交错排列,但这种设计将序列长度翻倍、引入二次方计算开销,还迫使 Transformer 在语义不兼容的异构 token 间做隐式解耦。论文提出 AttnLFA 和 AttnMVP 两种架构,核心思路是显式编码 item→action 的因果依赖,而非让注意力机制自己去猜。效果上,序列复杂度降低 50%,评估损失分别改善 0.29% 和 0.80%,训练时间减少 23% 和 12%。
HSTU 在 Meta 多个产品线上取得了 12.4% 的在线指标提升,但其交错序列设计的效率代价一直被默认接受。LinkedIn 的工作表明这个代价并非必要,因果结构的显式建模可以同时提升效果和效率。
Quantized Inference for OneRec-V2 (2603.11486)
快手团队将 LLM 领域成熟的 FP8 量化技术迁移到 OneRec-V2 上,这看似增量但意义深远。传统推荐模型的权重和激活值通常呈高幅值、高方差分布,对量化扰动极其敏感。论文通过分布分析实证表明,OneRec-V2 的数值统计特性显著更接近 LLM 而非传统推荐模型——这本身就是 GR 范式向 LLM 范式趋近的一个重要信号。
OneRec-V2 原始架构采用 Lazy Decoder-Only 设计,已将总计算量缩减 94%、训练资源降低 90%,支持扩展到 8B 参数。在此基础上,FP8 量化进一步实现端到端推理延迟降低 49%、吞吐量提升 92%,且线上 A/B 测试确认核心指标无下降。此前 xGR 通过分离 KV 缓存实现了 3.49 倍吞吐提升,RelayGR 通过跨阶段接力推理支持序列长度提升 1.5 倍——本文从数值精度维度补齐了 GR 推理优化的最后一块拼图。
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement Learning (2603.11901)
FlexRec 解决的是一个务实但被忽视的问题:LLM 推荐器如何在不同场景下按需切换优化目标?论文在闭集自回归排序设定下引入 RL 后训练,核心创新在于基于反事实交换的因果 item-level 奖励——在剩余候选池中做 counterfactual swap 来精细化信用分配,再结合 critic-guided 的不确定性感知缩放稳定训练。NDCG@5 提升高达 59%,Recall@5 提升高达 109.4%,泛化设定下 Recall@5 仍有 24.1% 的提升。该工作扩展自 Rec-R1,但在奖励设计和训练稳定性上做了实质性推进。不过目前仅有离线验证,缺乏大规模线上 A/B 测试。
Differentiable Geometric Indexing for End-to-End Generative Retrieval (2603.10409)
阿里巴巴团队在生成式检索的索引构建环节找到了两个深层矛盾:离散索引的不可微性阻断了梯度回传(Optimization Blockage),非归一化内积目标导致热门 item 在几何空间中压制长尾 item(Geometric Conflict)。DGI 的方案是双管齐下——用 Gumbel-Softmax 的 Soft Teacher Forcing 建立全可微路径,结合 Symmetric Weight Sharing 对齐量化器索引空间和检索器解码空间;再用单位超球面上的缩放余弦相似度替代内积 logit,从几何上解耦流行度偏差与语义相关性。在线电商平台验证中,DGI 在长尾场景表现尤为突出。生成式检索此前的工作如 TIGER 使用 RQ-VAE 进行离散 tokenization,本质上都受限于索引构建与下游检索目标的割裂——DGI 首次从可微分性和几何结构两个层面同时解决了这一问题。
五篇论文呈现出一个清晰的共同信号:GR 的核心挑战已从"如何用 Transformer 建模序列"转向系统级的全栈优化——后训练对齐(指数奖励加权 vs. RL)、注意力结构(因果重构 vs. 交错)、推理效率(FP8 量化)、索引设计(可微几何),每个环节都在向 LLM 的工程实践看齐,但又必须适配推荐场景的独特约束。
LLM Agent 与推理增强推荐
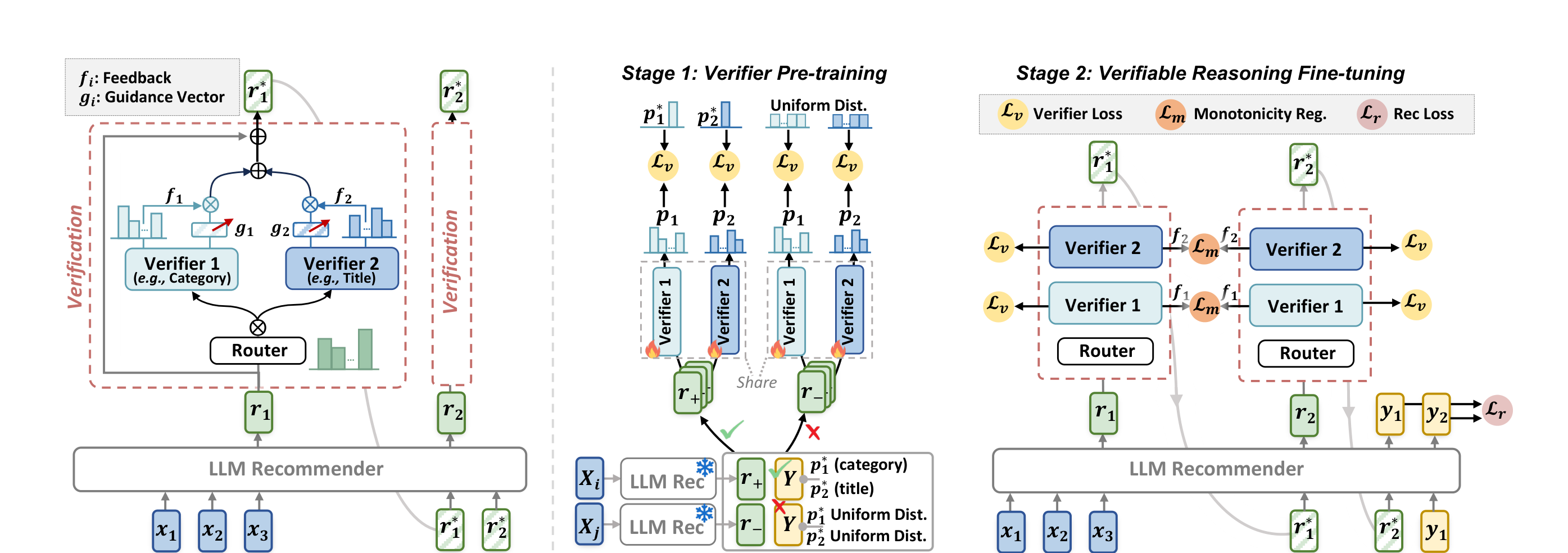
推荐系统正在经历一次角色转换:从被动的列表过滤器,进化为能主动调查、推理、验证的智能体。本周五篇论文分别从可验证推理、深度研究范式、多方协调、工具增强推理和自主记忆检索五个角度推动这一转变。
Verifiable Reasoning for LLM-based Generative Recommendation (2603.07725)
Meta 与新加坡国立大学联合提出 VRec,直指当前 LLM 推荐中"reason-then-recommend"范式的核心缺陷:推理链缺乏中间验证,导致同质化推理和错误累积。VRec 的解法是插入验证环节,形成"reason-verify-recommend"三段式。具体实现上,VRec 采用混合验证器(mixture of verifiers)确保多维度用户偏好的全面校验,同时引入代理预测目标(proxy prediction objective)来保障验证器本身的可靠性——验证器不准,验证就是空谈。四个真实数据集上的实验表明,VRec 在不牺牲效率的前提下显著提升了推荐效果和可扩展性。
此前 Reason4Rec 等工作已证明推理链对推荐有益,但 VRec 揭示了一个更深层的问题:推理链的质量需要显式约束,而非盲目信任 LLM 的自回归生成。这与近期 DiffuReason 通过扩散模型对推理结果去噪精炼的思路形成呼应——两者都在说同一件事:LLM 的推理输出需要"二次加工"。
Deep Research for Recommender Systems (2603.07605)
美团与人大合作的 RecPilot 做了一件更激进的事:直接取消推荐列表,用综合研究报告替代。这不是渐进式改进,而是交互范式的重新定义。RecPilot 由两个核心 Agent 构成:用户轨迹模拟代理自主探索物品空间,自进化报告生成代理将探索结果合成为结构化决策报告。传统推荐把"探索-比较-综合"的认知负担完全甩给用户,RecPilot 则让系统主动承担这些工作。公开数据集实验显示,生成的报告不仅建模用户行为的能力强,还具备高度说服力,显著降低了用户的物品评估成本。
这一思路与 ChainRec 的工具链路由、RecMind 的 Agent 推荐等工作共同指向一个方向:推荐系统的输出不再局限于 item list,而是可以是调查报告、对比分析、甚至决策建议。不过 RecPilot 目前仅在公开数据集上验证,距离美团实际场景的上线部署还有距离。
Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation (2603.10673)
中国科学技术大学提出的 TriRec 框架切入了一个被忽视的结构性问题:现有 Agent 推荐清一色以用户为中心,物品被当作被动实体,导致曝光集中和长尾低表达。TriRec 首次引入三方协调——用户效用、物品曝光、平台公平。两阶段架构中,Stage 1 赋予物品 Agent 个性化自我推广能力以突破冷启动壁垒,Stage 2 由平台 Agent 执行多目标序列重排,平衡三方利益。
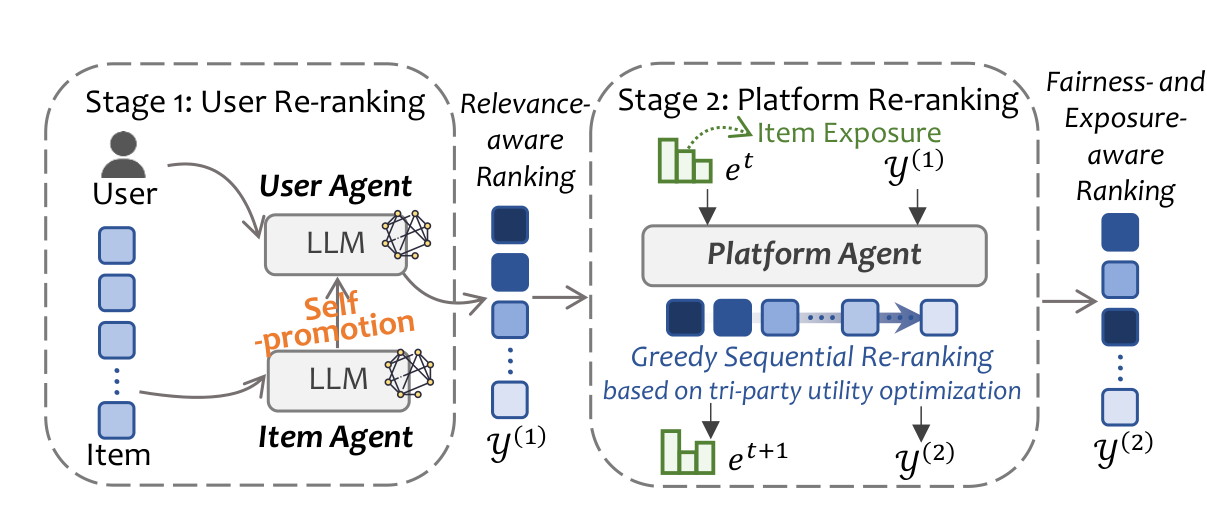
一个反直觉的发现是:物品自我推广可以同时提升公平性和推荐效果,挑战了"相关性与公平性必须权衡"的传统假设。从 AgentCF 将用户和物品都建模为 Agent 的协同学习,到 TriRec 引入平台 Agent 作为第三方仲裁者,Agent 推荐的参与方正在从双边扩展到多边。
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation (2603.09843)
人大与京东合作的 RecThinker 解决的是 Agent 推荐中的信息获取问题。现有方法要么依赖静态预定义工作流,要么在受限信息下做推理,面对碎片化用户画像或稀疏物品元数据时容易给出次优推荐。RecThinker 采用 Analyze-Plan-Act 范式:先分析用户-物品信息的充分性,再自主规划工具调用序列填补信息缺口。工具套件覆盖用户侧、物品侧和协同信息三个维度。训练流水线包含 SFT 阶段内化高质量推理轨迹和 RL 阶段优化决策准确性与工具使用效率。与 ChainRec 从专家轨迹构建工具库的思路类似,RecThinker 也在强调工具调用的可学习性,但更进一步地将"何时调用工具"的判断也交给了模型自主决策。
TA-Mem: Tool-Augmented Autonomous Memory Retrieval for LLM in Long-Term Conversational QA (2603.09297)
TA-Mem 虽然定位在长对话 QA,但其核心设计——多索引记忆库配合工具增强的自主检索 Agent——对对话式推荐有直接借鉴价值。传统记忆检索依赖预定义工作流或静态 top-k 相似度匹配,TA-Mem 让检索 Agent 自主选择检索工具(键值查找或相似度检索),并通过多轮迭代决定是否需要继续检索。在 LoCoMo 数据集上显著超越基线。对话式推荐场景中用户偏好随对话演进而变化,TA-Mem 的自适应检索机制比固定流程更能应对这种动态性。
五篇论文共同勾勒出一个清晰趋势:LLM 推荐正在从"单次推理出结果"走向"多步骤、可验证、工具辅助"的 Agent 化范式,系统的主动性和自主决策能力成为核心竞争力。
检索表示学习与嵌入空间优化
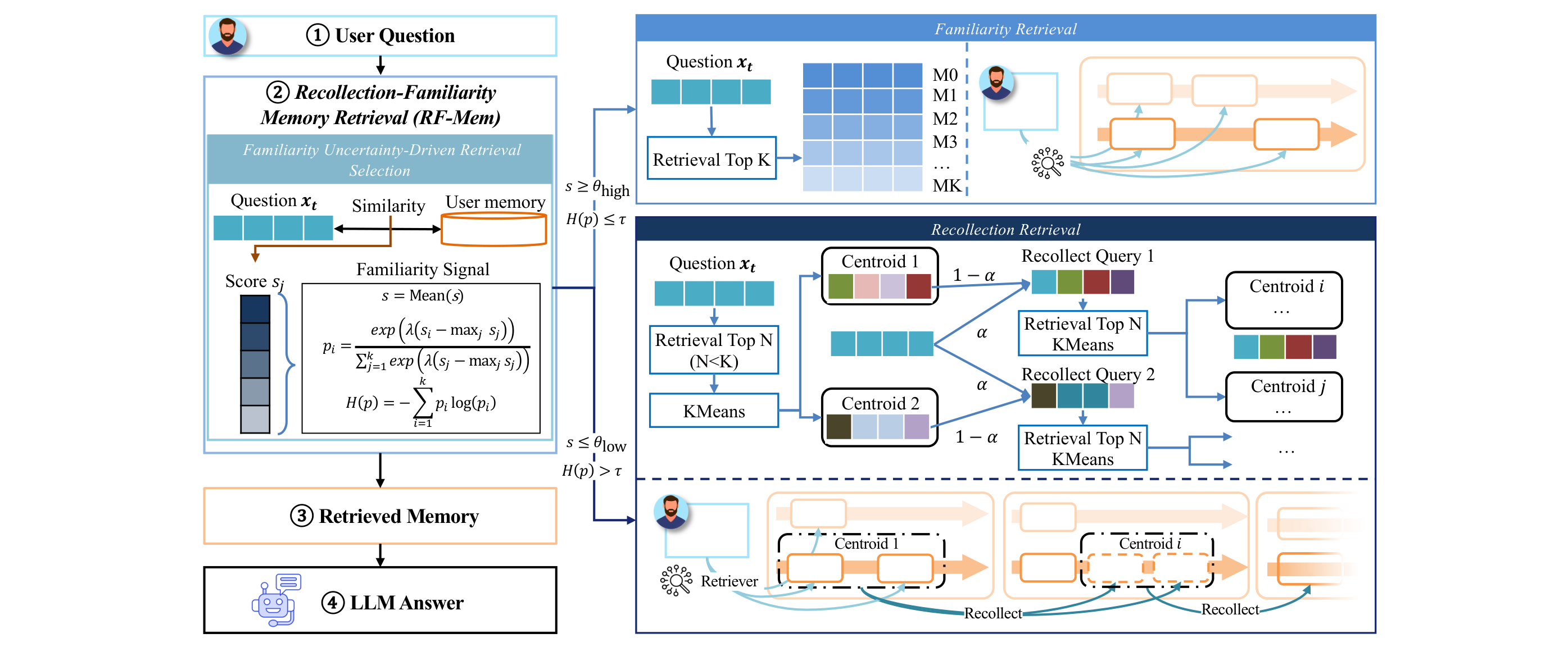
表示学习本周的核心矛盾很明确:嵌入空间该由谁来定义?是独立的编码器、GNN 的消息传递、还是 LLM 自身的隐藏状态?五篇论文从不同入口切入这个问题,给出了截然不同的答案。
Evoking User Memory: Personalizing LLM via Recollection-Familiarity Adaptive Retrieval (2603.09250)
华为联合大连理工等提出的 RF-Mem 把认知科学的双过程记忆理论搬进了检索管线。核心观察是:现有 RAG 系统要么把全部用户历史塞进 prompt(成本不可控),要么做一次 top-K 相似度检索(只能抓表层匹配)。RF-Mem 通过均值分数和熵两个信号量化"熟悉度"——高熟悉度走快速 top-K 路径,低熟悉度则激活回忆路径:先对候选记忆聚类,再用 alpha-mix 在嵌入空间中迭代扩展查询的证据覆盖范围,模拟人类的联想式重建。
这个设计的精巧之处在于用熵作为路由信号——熵低意味着检索器对当前查询的判断一致性高,可以直接出结果;熵高则说明嵌入空间中的邻域分布模糊,需要更深层的上下文重建。三个基准测试上,RF-Mem 在固定预算和延迟约束下一致优于单次检索和全上下文推理。相比 RLMRec 提出的跨视图对齐框架(通过互信息最大化将 LLM 语义空间与协同信号对齐),RF-Mem 走的是检索侧的自适应路由,不改嵌入空间本身的构建方式,而是在使用层面做动态调度。
P²GNN: Two Prototype Sets to boost GNN Performance (2603.09195)
Amazon 这篇直击 MP-GNN 的两个老毛病:过度依赖局部邻域、对异配边(heterophily)束手无策。P²GNN 的解法是引入两组原型:第一组作为所有节点的"全局邻居",让每个节点在消息传递时都能接触到全局上下文;第二组通过将消息对齐到聚类原型来实现去噪。这个设计是 plug-and-play 的,可以叠加在 GCN、GAT、GraphSAGE 之上。18 个数据集的实验覆盖了电商私有数据和公开数据,在节点推荐和分类任务上均取得最优平均排名,并且在电商场景超越了生产模型。
从表示学习的视角看,原型本质上是在嵌入空间中锚定了一组全局参考点。Spotify 的 2T-HGNN 通过异构图结构引入全局信息(新有声书开始率 +46%),而 P²GNN 用更轻量的原型机制达到了类似效果,且不需要显式建模异构关系。
One Model Is Enough: Native Retrieval Embeddings from LLM Agent Hidden States (2603.08429)
这篇论文提出了一个激进但合理的问题:LLM agent 在生成检索查询时,其隐藏状态已经编码了完整的对话上下文,为什么还要再跑一个独立的嵌入模型?作者在 LLM 之上加了一个轻量投影头(projection head),直接将隐藏状态映射到嵌入空间,通过对齐损失、对比损失和排序蒸馏损失联合训练。在 QReCC 对话搜索基准上,该方法保留了基线 97% 的检索质量(Recall@10 和 MRR@10),同时消除了独立嵌入模型带来的基础设施复杂度和延迟。
这个方向与 NoteLLM 将笔记压缩为单个 special token 并用对比学习学习嵌入的思路一脉相承——都是让 LLM 自己生产嵌入而非依赖外部编码器。不过 97% 的保留率意味着还有质量差距,在工业场景中这 3% 可能意味着不小的业务损失。
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning (2603.08159)
清华的 TIER 方法关注的是嵌入空间的结构性——现有文本丰富网络(TRN)的表示学习大多只建模扁平语义,忽略了从粗到细的层次结构。TIER 分三步走:先用相似性引导的对比学习构建聚类友好的嵌入空间,然后在其上做层次化 K-Means 并用 LLM 精化聚类结果,最后引入基于同源相关系数(cophenetic correlation coefficient)的正则化损失,强制嵌入空间保持层次结构一致性。这个正则化设计值得注意——它不是简单地加层次约束,而是用树状聚类的数学度量来量化嵌入空间的层次保真度。在多个领域的数据集上显著优于现有方法。
Why Large Language Models can Secretly Outperform Embedding Similarity in Information Retrieval (2603.08077)
格罗宁根大学这篇提供了一个有趣的理论视角:嵌入相似度本质上是对"相关性"的短视诠释。作者将 LLM-Based Relevance Judgment Systems(LLM-RJS)与 Neural Embedding Retrieval Systems(NERS)在 TREC-DL 2019 上做了对比,结果并未观察到显著提升——但原因不在模型,而在评估。深入分析发现,人工标注本身也存在短视问题,LLM-RJS 通过推理产生的"假阳性"实际上是标注错误。这个结论对上面几篇嵌入优化的工作构成了有意思的反思:当我们不断优化嵌入空间的几何结构时,瓶颈可能不在表示本身,而在于"相关性"这个概念的度量方式已经需要更新了。
五篇论文合在一起勾勒出一个清晰的趋势:表示学习正在从"训练一个好的嵌入模型"走向"让嵌入空间与使用场景深度耦合"——无论是 RF-Mem 的自适应路由、P²GNN 的全局原型锚定,还是直接从 LLM 隐藏状态中提取嵌入,都不再把嵌入空间当作一个静态的、独立优化的组件。
联邦推荐、隐私合规与其他方向
本周"其他"主题汇集了联邦推荐、机器遗忘、检索压缩、广告竞价和经典模型泛化等多个方向的工作,共同特征是都在各自细分领域推动基础方法论的精细化。
Sharpness-Aware Minimization for Generalized Embedding Learning in Federated Recommendation (2603.11503)
联邦推荐中 item embedding 的泛化一直是个棘手问题——跨设备场景下本地数据既异构又稀疏,embedding 很容易过拟合到局部分布。FedRecGEL 换了个视角,把联邦推荐重构为以 item 为中心的多任务学习问题,每个客户端视为一个"任务"。在此框架下引入 Sharpness-Aware Minimization(SAM)来寻找损失平坦区域的解,从而稳定全局 embedding 的训练。四个数据集上 Recall@20 相比 FedAvg、FedProx、SCAFFOLD 等基线提升 3.2%-8.7%。思路清晰,但尚无工业规模验证。SAM 此前在推荐领域的应用并不多见,这种从优化器层面切入联邦泛化问题的路径有一定启发性。
Federated Learning and Unlearning for Recommendation with Personalized Data Sharing (2603.11610)
FedShare 关注的是联邦推荐中一个更细粒度的隐私控制问题:用户不只是"全共享"或"全本地",而是可以选择性地共享部分交互数据,并在事后撤回共享。框架在服务端利用共享数据构建高阶用户-物品图,通过对比学习对齐本地和全局表示。遗忘阶段的设计是亮点——提出 contrastive unlearning 机制,仅需少量历史 embedding 快照即可选择性移除已撤回数据的影响,避免了现有方法需要存储大量历史梯度的开销。三个公开数据集验证了学习和遗忘两个阶段的有效性。与上一篇 FedRecGEL 共同反映出联邦推荐从"能用"向"精细化控制"的演进。
Modeling Stage-wise Evolution of User Interests for News Recommendation (2603.10471)
新闻推荐的时效性决定了用户兴趣建模必须同时覆盖长短期。这篇文章的做法是将历史交互图按时间切分为阶段性子图(stage-wise temporal subgraphs),用 GCN 捕获全局协同信号,再在局部子图上双管齐下:LSTM 建模近期兴趣的渐进演化,self-attention 捕获长程时序依赖。架构不算新颖——BST(2019)早已将 self-attention 引入行为序列建模,DSIN 也做过 session 级切分——但将图结构与时序建模在新闻场景下显式解耦的思路仍有价值。两个大规模数据集上持续优于强基线,不过缺少线上验证。
A Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models (2603.09933)
ColBERT 类 late-interaction 模型的存储开销一直是部署痛点——每个文档 token 都要保留一个稠密向量。现有剪枝方法多基于 IDF 统计或位置启发式,缺乏理论基础。这篇文章用超空间几何给出了一个优雅的形式化:将 token 剪枝建模为 embedding 空间中的 Voronoi cell 估计问题,每个 token 的重要性由其 Voronoi 区域的"影响范围"度量。在 MS MARCO 和 TREC DL 上实现 30%-50% 索引压缩同时保持检索质量。近期 Col-Bandit 从查询侧做零样本剪枝可将 MaxSim FLOPs 降低 5 倍,FastLane 用可学习路由降低 30 倍计算量——本文从文档侧的 Voronoi 视角与它们形成互补。
ERASE -- A Real-World Aligned Benchmark for Unlearning in Recommender Systems (2603.08341)
推荐系统的机器遗忘缺乏贴合实际的评测标准。ERASE 补上了这个缺口:覆盖协同过滤、会话推荐、下一篮子推荐三类任务,在 9 个数据集和 9 个 SOTA 模型上评估 7 种遗忘算法,生成超过 600GB 可复用实验数据。关键发现是——近似遗忘在部分场景可匹配完全重训练的效果,但鲁棒性差异巨大:通用方法在 attention 和 RNN 模型上的重复遗忘场景表现较差,推荐专用遗忘方法更稳定。结合 FedShare 的 contrastive unlearning 设计,遗忘/隐私合规正在成为推荐系统的一个独立研究轴。
A Lightweight MPC Bidding Framework for Brand Auction Ads (2603.07721)
字节跳动这篇文章另辟蹊径——品牌广告不同于效果广告,用户互动模式稳定、反馈回路快,不需要复杂的 ML 模型。基于此洞察,提出用模型预测控制(MPC)框架替代传统机器学习竞价,核心是用在线保序回归(isotonic regression)直接从流式数据构建单调的 bid-to-spend 和 bid-to-conversion 映射。计算开销极低,全在线运行。仿真结果显示支出效率和成本控制显著优于基线。思路务实,但只有仿真没有线上 A/B 测试——对于字节跳动这样有充足流量的平台,这种"只差最后一步验证"让人意犹未尽。
Generalizing Linear Autoencoder Recommenders with Decoupled Expected Quadratic Loss (2603.07402)
线性自编码器(LAE)在推荐中因简洁高效而持续受关注。Steck 2020 年提出的 EDLAE 只有超参数 b=0 时存在闭式解,限制了模型容量。DEQL 将目标函数解耦为 Decoupled Expected Quadratic Loss,推导出 b>0 范围的闭式解,并基于 Miller 矩阵逆定理保证计算可行。MovieLens-1M 和 Netflix 上 Recall@20 和 NDCG@20 比 b=0 基线提升约 1%-3%。增量改进但方向扎实——在深度模型主导的时代,LAE 类方法的数学优雅和可解释性仍有其独特价值。
联邦推荐的两篇(FedRecGEL、FedShare)和遗忘基准(ERASE)共同指向一个趋势:隐私合规和数据主权正从"可选项"变为推荐系统的基础设施级需求,相关方法论正在快速成熟。
值得关注的方向
生成式推荐的全栈工业化
本周五篇 GR 论文同时覆盖了后训练对齐、注意力架构、推理量化、RL 微调和端到端索引——这种多维度并发推进说明 GR 已进入系统工程阶段。指数奖励加权 SFT(Netflix/Meta)的简洁性和理论保证使其极具工业吸引力;FP8 量化(快手)验证了 GR 模型的数值特性已足够接近 LLM,可以直接复用 LLM 的推理优化工具链;AttnLFA/AttnMVP(LinkedIn)证明了交错序列设计的效率代价并非必要。Netflix、Meta、快手、LinkedIn、阿里等工业团队在同一周密集贡献,预示 GR 将在 2026 年下半年迎来更多大规模部署案例。下一步可能是这些优化的组合——例如因果注意力 + FP8 量化 + 指数奖励加权的一体化方案。
Agent 化推荐的多方协调
Agent 推荐正在从"用户代理"扩展到多方参与。TriRec(中科大)首次引入物品 Agent 和平台 Agent,实验表明物品自我推广可以同时提升公平性和准确性。RecPilot(美团/人大)直接取消推荐列表,用综合报告替代传统交互范式。RecThinker(人大/京东)和 TA-Mem 则在工具调用和记忆检索层面完善 Agent 的信息获取能力。这些工作距离工业部署还有距离,但共同描绘了推荐系统从"被动过滤器"向"主动助手"的演进方向。实际应用前景包括高客单价决策(房产、汽车、教育)和需要深度信息综合的场景。
隐私合规成为基础设施级需求
FedRecGEL 从优化器层面稳定联邦推荐的嵌入泛化,FedShare 支持细粒度数据共享与撤回,ERASE 提供了首个覆盖三类推荐任务的遗忘学习基准(600GB+ 可复用数据)。三篇论文的组合信号是:联邦学习、选择性遗忘和隐私合规正从零散的学术探索汇聚成一个连贯的技术栈。随着 GDPR 执法力度加大和各国数据保护法规趋严,推荐系统的隐私能力正在从"加分项"变为"准入门槛"。浙江大学、悉尼科技大学、阿姆斯特丹大学等学术团队在持续推进,但工业界的大规模验证仍是关键缺口。
本周论文速览
生成式推荐的架构与后训练优化
Robust Post-Training for Generative Recommenders: Why Exponential Reward-Weighted SFT Outperforms RLHF — 提出指数奖励加权 SFT(w=exp(r/λ))作为 GR 后训练方法,理论证明策略改进保证,在四个数据集上一致优于 DPO/IPO/KTO 等 RLHF 变体。
Beyond Interleaving: Causal Attention Reformulations for Generative Recommender Systems — 提出 AttnLFA/AttnMVP 架构消除 item-action 交错依赖,序列长度减半,训练加速 12-23%,评估损失改善 0.29-0.80%。
Quantized Inference for OneRec-V2 — 将 FP8 量化适配至 OneRec-V2,推理延迟降低 49%、吞吐提升 92%,线上 A/B 确认核心指标无下降。
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement Learning — 基于因果 item-level 奖励和不确定性感知缩放的 RL 后训练框架;NDCG@5 提升高达 59%,Recall@5 提升高达 109.4%。
Differentiable Geometric Indexing for End-to-End Generative Retrieval — 通过 Gumbel-Softmax 全可微索引和超球面余弦相似度解决 GR 中的优化阻塞和长尾偏差;线上电商平台验证有效。
LLM Agent 与推理增强推荐
Verifiable Reasoning for LLM-based Generative Recommendation — 提出 reason-verify-recommend 范式 VRec,混合验证器在推理过程中插入中间验证;四个数据集验证有效性。
Deep Research for Recommender Systems — 提出 RecPilot 多 Agent 框架,用用户轨迹模拟和自进化报告生成替代传统列表式推荐。
Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation — 首个三方 Agent 框架 TriRec,引入物品自我推广和平台多目标重排;同步提升准确性与公平性。
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation — Analyze-Plan-Act 范式配合专用工具集和 SFT+RL 训练;实现推荐中的自主信息获取。
TA-Mem: Tool-Augmented Autonomous Memory Retrieval for LLM in Long-Term Conversational QA — 多索引记忆数据库配合工具增强检索 Agent;在长对话场景下自适应选择检索策略。
检索表示学习与嵌入空间优化
Evoking User Memory: Personalizing LLM via Recollection-Familiarity Adaptive Retrieval — 借鉴认知科学双过程理论,基于熟悉度不确定性自适应切换快速 top-K 和迭代回忆检索路径。
P²GNN: Two Prototype Sets to boost GNN Performance — 通过全局邻居原型和聚类对齐原型增强 GNN 消息传递;在 18 个数据集上排名第一,电商场景超越生产模型。
One Model Is Enough: Native Retrieval Embeddings from LLM Agent Hidden States — 轻量投影头将 LLM 隐藏状态直接映射为检索向量,消除独立嵌入模型;保留 97% 检索质量。
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning — 构建隐式层次分类并通过同源相关系数正则化对齐嵌入;兼顾粗细粒度语义。
Why Large Language Models can Secretly Outperform Embedding Similarity in Information Retrieval — 分析发现 LLM 推理能克服嵌入相似性的"短视"局限,但现有标注数据集无法充分评估此优势。
联邦推荐、隐私合规与其他
Sharpness-Aware Minimization for Generalized Embedding Learning in Federated Recommendation — 引入锐度感知最小化稳定联邦推荐中的物品嵌入学习;Recall@20 提升 3.2%-8.7%。
Federated Learning and Unlearning for Recommendation with Personalized Data Sharing — 支持个性化数据共享与对比遗忘的联邦推荐框架 FedShare。
Modeling Stage-wise Evolution of User Interests for News Recommendation — 分阶段时序子图建模用户兴趣演化,结合 LSTM 和 self-attention 捕获多尺度动态。
A Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models — 基于 Voronoi 几何框架的 token 剪枝方法;减少 ColBERT 索引存储 30-50%。
ERASE -- A Real-World Aligned Benchmark for Unlearning in Recommender Systems — 覆盖三类推荐任务的大规模遗忘学习基准;生成 600GB+ 可复用实验数据。
A Lightweight MPC Bidding Framework for Brand Auction Ads — 针对品牌广告的轻量级 MPC 竞价框架;用在线保序回归替代复杂 ML 模型。
Generalizing Linear Autoencoder Recommenders with Decoupled Expected Quadratic Loss — 将 EDLAE 泛化到 b>0 超参数范围;Recall@20 和 NDCG@20 提升 1-3%。